第1章 Alink快速上手
答疑
1、查看书中的链接
【问题】
下面截图中,1-1和1-4链接在哪?

【答复】
按出版社要求,书中无法放链接的HTTP地址,可以访问如下页面查看:
- Java版的数据和资料链接:http://alinklab.cn/tutorial/book_java_00_reference.html
- Python版的数据和资料链接:http://alinklab.cn/tutorial/book_python_00_reference.html
2、预测一条数据从14秒到8毫秒
【问题】
Alink训练出的模型,再去预测为啥这么慢,预测一条数据需要14秒,用sklearn训练的模型预测只需要19毫秒,有大佬知道原因吗?
System.out.println("开始预测");
long start = System.currentTimeMillis();
//定义数据源
BatchOperator<?> data = new MemSourceBatchOp(new String[] {"svision-online.de/mgfi/administrator/components/com_babackup/classes/fx29id1.txt"}, "url");;
//模型效果评估
BatchOperator<?> predict = model.transform(data);
predict.select(new String[] {"url", "pred"}).print();
System.out.println("时间:" + (System.currentTimeMillis() - start));用户根据反馈,改成LocalPredictor,预测时间 8毫秒
【答复】
你计算的是任务运行的时间。要是使用任务预测的话,你可以多计算一些条,譬如100万,这样可以摊平任务的起停时间;或者使用LocalPredictor测试。
你的场景需要使用LocalPredictor。参见教程1.5.5节 嵌入预测服务系统 ;23.4.2节 嵌入式预测
3、随机森林模型有模型储存方法吗
【问题】
随机森林模型有模型储存方法吗,就是我把训练好的模型保存下来,下次直接拿来用
【答复】
有啊,而且分批式训练保存及Pipeline训练保存两种方式。随机森林模型与其它分类模型的储存方法是一样的,参见教程1.5节简单示例中演示的逻辑回归模型。
4、切换Flink版本的问题
【问题】
代码没动,切换了flink版本就运行不了了,这是bug吗?flink.version 1.10.0没有问题,高于1.10的都运行不了
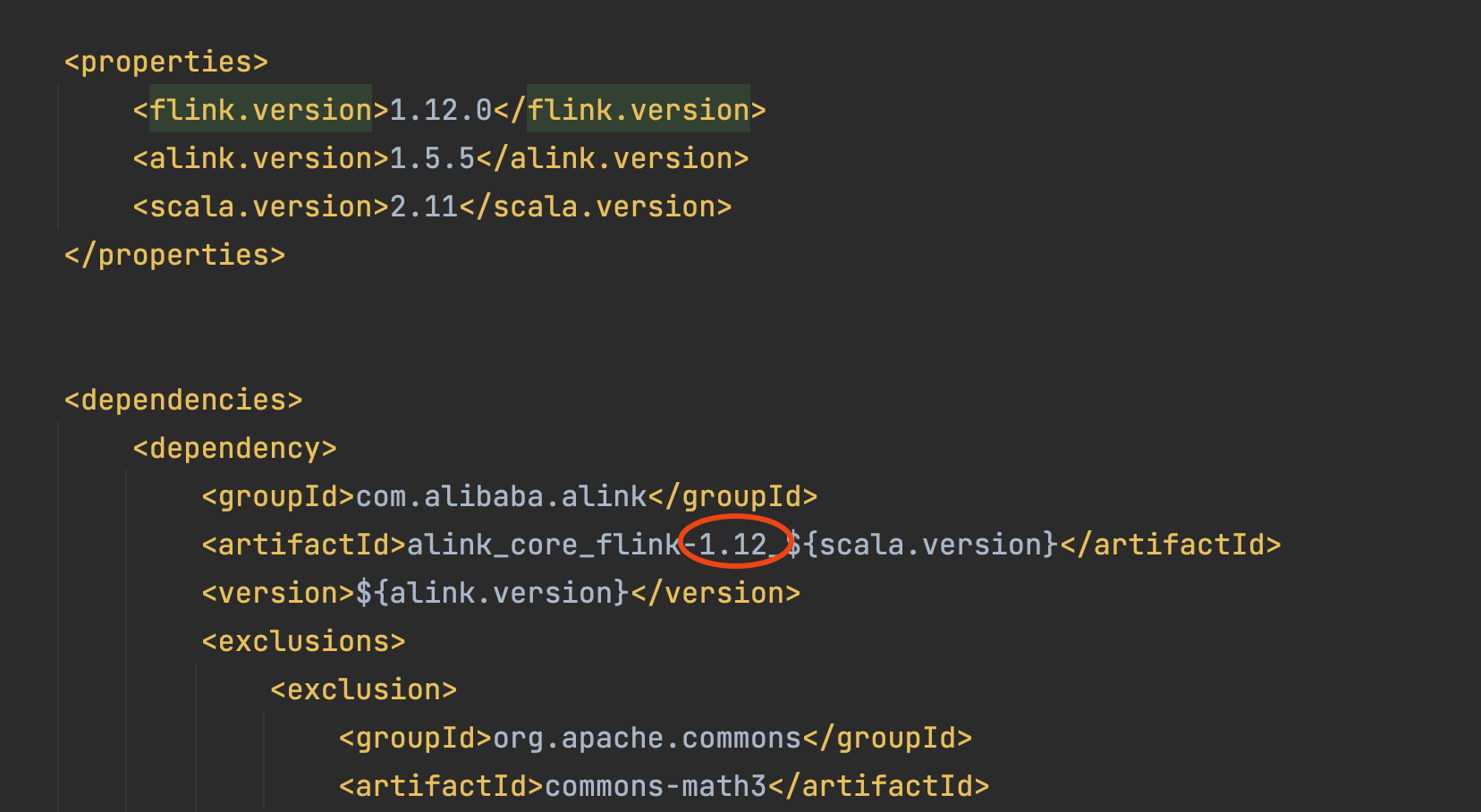
【答复】
这是由于没有切换Flink相关的jar包引起的。链接 https://github.com/alibaba/Alink#flink-112-%E7%9A%84-maven-%E4%BE%9D%E8%B5%96 中列举了使用不同的Flink版本所需的算法包情况。可以看到Flink1.9和1.10需要3个jar包,而Flink1.11、1.12和1.23则需要4个jar包。所以从Flink1.9到1.10,只需要修改版本号就行了;但是到1.12修版本号是不够的,还需要再引入jar包。
5、将array数据作为数据源
【问题】
请问下alink可以读取array的数据去建模吗?
【答复】
可以的,参见教程1.5.2节,分别展示了如何使用Java和Python进行转换。特别地,对于Python版教程有专门的章节进行介绍,详见第7.6节 “Python 数组、DataFrame 形式的数据和 Alink 批式数据之间的相互转换”。
Java:
BatchOperator <?> train_set = new MemSourceBatchOp(
new Row[] {
Row.of(2009, 0.5),
Row.of(2010, 9.36),
Row.of(2011, 52.0),
Row.of(2012, 191.0),
Row.of(2013, 350.0),
Row.of(2014, 571.0),
Row.of(2015, 912.0),
Row.of(2016, 1207.0),
Row.of(2017, 1682.0),
},
new String[] {"x", "gmv"}
);注意:这里使用了Row[]数组,也可以使用Object[][]数组。
Python:
df = pd.DataFrame(
[
[2009, 0.5],
[2010, 9.36],
[2011, 52.0],
[2012, 191.0],
[2013, 350.0],
[2014, 571.0],
[2015, 912.0],
[2016, 1207.0],
[2017, 1682.0]
]
)
train_set = BatchOperator.fromDataframe(df, schemaStr='x int, gmv double')6、批式和流式模型预测组件能使用一样的调用方式吗?
【问题】
在第一章中,流处理模式预测的时候,想和批处理模式一样使用linkFrom方法连接,会报错,怎么解决呀?这里是不是增加一个方法,让批处理和流处理能一样的方式调用呢?
【答复】
可以使用setModelFilePath方法。教程1.5.2节和1.5.3节的例子,可以写成如下形式。
//批式任务
new MemSourceBatchOp(new Integer[] {2018, 2019}, "x")
.select("x, x*x AS x2")
.link(
new LinearRegPredictBatchOp()
.setModelFilePath(DATA_DIR + "gmv_reg.model")
.setPredictionCol("pred")
)
.print();
//流式任务
new MemSourceStreamOp(new Integer[] {2018, 2019}, "x")
.select("x, x*x AS x2")
.link(
new LinearRegPredictStreamOp()
.setModelFilePath(DATA_DIR + "gmv_reg.model")
.setPredictionCol("pred")
)
.print();
StreamOperator.execute();7、不加载Flink的情况下,使用LocalPredictor
【问题】
LocalPredictor也需要加载flink-runtime环境么?
我在调用LocalPredictor的时候,下面是代码片段:
String schema ="user_id VARCHAR, item_id VARCHAR, is_click INT, u_cl_t_7 INT, u_cl_t_30 INT, u_cl_t_60 INT, u_ac_n_7 INT, u_ac_n_30 INT, u_act_n_60 INT, u_act_n_180 INT, u_exp_c_60 INT, u_exp_c_180 INT, u_ctr_60 FLOAT, u_ctr_180 FLOAT, u_avg_v_60 FLOAT, u_avg_v_180 FLOAT, gender VARCHAR, age VARCHAR, is_ter_5g VARCHAR, pro_of_nu VARCHAR, u_s_g_t_180_1st VARCHAR, u_s_g_t_180_2nd VARCHAR, u_s_g_t_180_3rd VARCHAR, u_s_g_t_60_1st VARCHAR, u_s_g_t_60_2nd VARCHAR, u_s_g_t_60_3rd VARCHAR, u_big_cat_hobby_1st_7 VARCHAR, u_big_cat_hobby_2nd_7 VARCHAR, u_big_cat_hobby_3rd_7 VARCHAR, u_second_cat_hobby_1st_JD_30 VARCHAR, u_second_cat_hobby_2nd_JD_30 VARCHAR, u_second_cat_hobby_3rd_JD_30 VARCHAR, u_second_cat_hobby_1st_PZ_7 VARCHAR, u_second_cat_hobby_2nd_PZ_7 VARCHAR, u_second_cat_hobby_3rd_PZ_7 VARCHAR, u_is_search_5g_7 VARCHAR, u_is_search_broadband_7 VARCHAR, u_is_search_flow_pac_7 VARCHAR, u_is_search_bill_buy_7 VARCHAR, u_is_search_pac_7 VARCHAR, u_is_search_pac_change_7 VARCHAR, u_is_search_card_acti_7 VARCHAR, u_is_search_score_7 VARCHAR, u_is_search_sign_in_7 VARCHAR, u_is_search_bill_7 VARCHAR, id VARCHAR, g_ty VARCHAR, i_u_cli_7 INT, i_u_cli_30 INT, i_u_cli_60 INT, i_u_cli_180 INT, i_cl_n_7 INT, i_cl_n_30 INT, i_cl_n_60 INT, i_cl_n_180 INT, i_exp_co_7 INT, i_exp_co_30 INT, i_exp_co_60 INT, i_exp_co_180 INT, i_ct_7 FLOAT, i_ct_30 FLOAT, i_ct_60 FLOAT, i_ct_180 FLOAT, i_big_cat_cli_rate_7 VARCHAR, i_cli_user_age_180_1st VARCHAR, i_cli_user_age_180_2nd VARCHAR, i_cli_user_gen_180_1st VARCHAR, i_cli_user_pro_180_1st VARCHAR, i_cat_2nd VARCHAR, i_keywords_search_cat_2nd VARCHAR";
PipelineModel loadedModel = PipelineModel.load("D:\\working\\worker\\sparrow\\ftrl_local_model.ak");
LocalPredictor localPredictor = loadedModel.collectLocalPredictor(schema);
Row row =Row.of("17633932694","3420169c25f54c078310c65684b7276b",0,2,4,4,9,11,11,11,289,291,0.0381,0.0378,4.8167,1.6167,"01","22","0","076","1000","+1","+1","1000","+1","+1","1000","+1","+1","+1","+1","+1","","","","0","0","0","0","0","0","0","0","0","0","1534017704082939905","1000",388,4712,4712,4712,405,4974,4974,4974,3612691,8157489,8157489,8157489,0.0001,0.0006,0.0006,0.0006,"0.001",2,"4","01","051","+1","I");
Row resultRow = localPredictor.map(row);报了如下的错误,我还需要怎么修正
java.lang.IllegalStateException: No ExecutorFactory found to execute the application. at org.apache.flink.core.execution.DefaultExecutorServiceLoader.getExecutorFactory(DefaultExecutorServiceLoader.java:88) at org.apache.flink.api.java.ExecutionEnvironment.executeAsync(ExecutionEnvironment.java:1043) at org.apache.flink.api.java.ExecutionEnvironment.execute(ExecutionEnvironment.java:958) at org.apache.flink.api.java.ExecutionEnvironment.execute(ExecutionEnvironment.java:942) at com.alibaba.alink.operator.batch.BatchOperator.collect(BatchOperator.java:690) at com.alibaba.alink.operator.batch.BatchOperator.collect(BatchOperator.java:669) at com.alibaba.alink.pipeline.PipelineModel.collectLocalPredictor(PipelineModel.java:287) at com.alibaba.alink.pipeline.LocalPredictable.collectLocalPredictor(LocalPredictable.java:16) at LocalPredictorMain.main(LocalPredictorMain.java:11)
【答复】
可以直接使用LocalPredictor的构造方法,输入模型路径和schema信息。代码如下
String schema ="user_id VARCHAR, item_id VARCHAR, is_click INT, u_cl_t_7 INT, u_cl_t_30 INT, u_cl_t_60 INT, u_ac_n_7 INT, u_ac_n_30 INT, u_act_n_60 INT, u_act_n_180 INT, u_exp_c_60 INT, u_exp_c_180 INT, u_ctr_60 FLOAT, u_ctr_180 FLOAT, u_avg_v_60 FLOAT, u_avg_v_180 FLOAT, gender VARCHAR, age VARCHAR, is_ter_5g VARCHAR, pro_of_nu VARCHAR, u_s_g_t_180_1st VARCHAR, u_s_g_t_180_2nd VARCHAR, u_s_g_t_180_3rd VARCHAR, u_s_g_t_60_1st VARCHAR, u_s_g_t_60_2nd VARCHAR, u_s_g_t_60_3rd VARCHAR, u_big_cat_hobby_1st_7 VARCHAR, u_big_cat_hobby_2nd_7 VARCHAR, u_big_cat_hobby_3rd_7 VARCHAR, u_second_cat_hobby_1st_JD_30 VARCHAR, u_second_cat_hobby_2nd_JD_30 VARCHAR, u_second_cat_hobby_3rd_JD_30 VARCHAR, u_second_cat_hobby_1st_PZ_7 VARCHAR, u_second_cat_hobby_2nd_PZ_7 VARCHAR, u_second_cat_hobby_3rd_PZ_7 VARCHAR, u_is_search_5g_7 VARCHAR, u_is_search_broadband_7 VARCHAR, u_is_search_flow_pac_7 VARCHAR, u_is_search_bill_buy_7 VARCHAR, u_is_search_pac_7 VARCHAR, u_is_search_pac_change_7 VARCHAR, u_is_search_card_acti_7 VARCHAR, u_is_search_score_7 VARCHAR, u_is_search_sign_in_7 VARCHAR, u_is_search_bill_7 VARCHAR, id VARCHAR, g_ty VARCHAR, i_u_cli_7 INT, i_u_cli_30 INT, i_u_cli_60 INT, i_u_cli_180 INT, i_cl_n_7 INT, i_cl_n_30 INT, i_cl_n_60 INT, i_cl_n_180 INT, i_exp_co_7 INT, i_exp_co_30 INT, i_exp_co_60 INT, i_exp_co_180 INT, i_ct_7 FLOAT, i_ct_30 FLOAT, i_ct_60 FLOAT, i_ct_180 FLOAT, i_big_cat_cli_rate_7 VARCHAR, i_cli_user_age_180_1st VARCHAR, i_cli_user_age_180_2nd VARCHAR, i_cli_user_gen_180_1st VARCHAR, i_cli_user_pro_180_1st VARCHAR, i_cat_2nd VARCHAR, i_keywords_search_cat_2nd VARCHAR";
LocalPredictor localPredictor = new LocalPredictor("D:\\working\\worker\\sparrow\\ftrl_local_model.ak", schema);
Row row = Row.of("17633932694","3420169c25f54c078310c65684b7276b",0,2,4,4,9,11,11,11,289,291,0.0381,0.0378,4.8167,1.6167,"01","22","0","076","1000","+1","+1","1000","+1","+1","1000","+1","+1","+1","+1","+1","","","","0","0","0","0","0","0","0","0","0","0","1534017704082939905","1000",388,4712,4712,4712,405,4974,4974,4974,3612691,8157489,8157489,8157489,0.0001,0.0006,0.0006,0.0006,"0.001",2,"4","01","051","+1","I");
Row resultRow = localPredictor.map(row);