第2章 系统概况与核心概念
答疑
1、组件分类(Pipeline,批组件,流组件)的区别
【问题】
我能问一下组件这些分类(Pipeline,批组件,流组件)有什么区别吗?
【答复】
Alink教程第2章有详细介绍。简单地说,由批式组件和流式组件,可以构建出复杂的任务,组件和其连线可以构成有向无环图。但有些常用场景,我们所用的组件只需单输入单输出,连接成“Pipeline”,可以用于批式场景也可以用在流式场景。
2、execute(), print(), collect()触发执行的问题
【问题】
代码报错,如截图所示
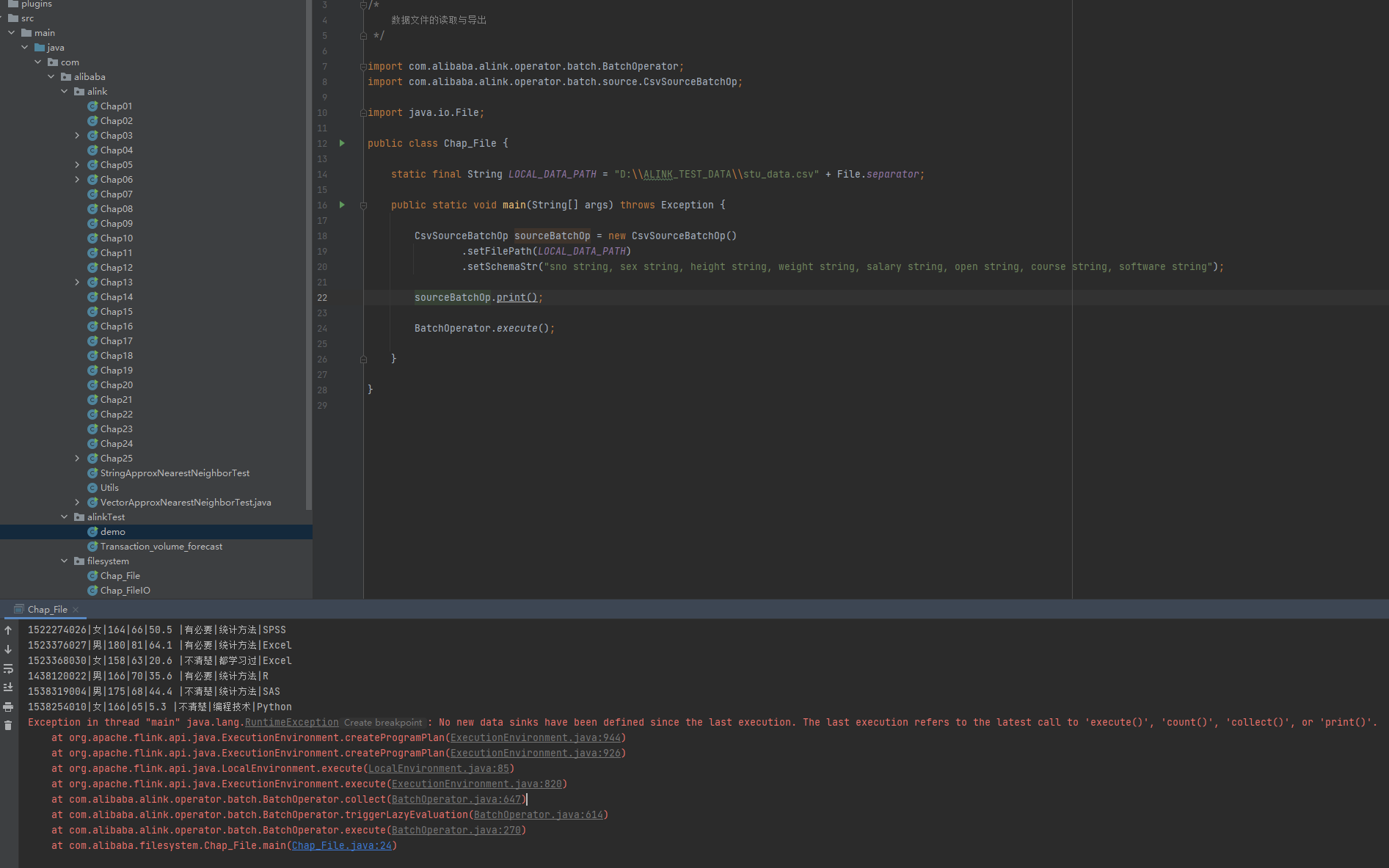
【答复】
把BatchOperator.execute();这行去掉,前面的print已经触发了执行。
Alink提供了多种触发执行的方式,给我们带来便利的同时,也带来了些困惑。建议研究教程 2.5节 触发 Alink 任务的执行 。以及补充内容 http://alinklab.cn/tutorial/book_java_02_5_1.html
3、如何打印全部记录
【问题】
如截图所示
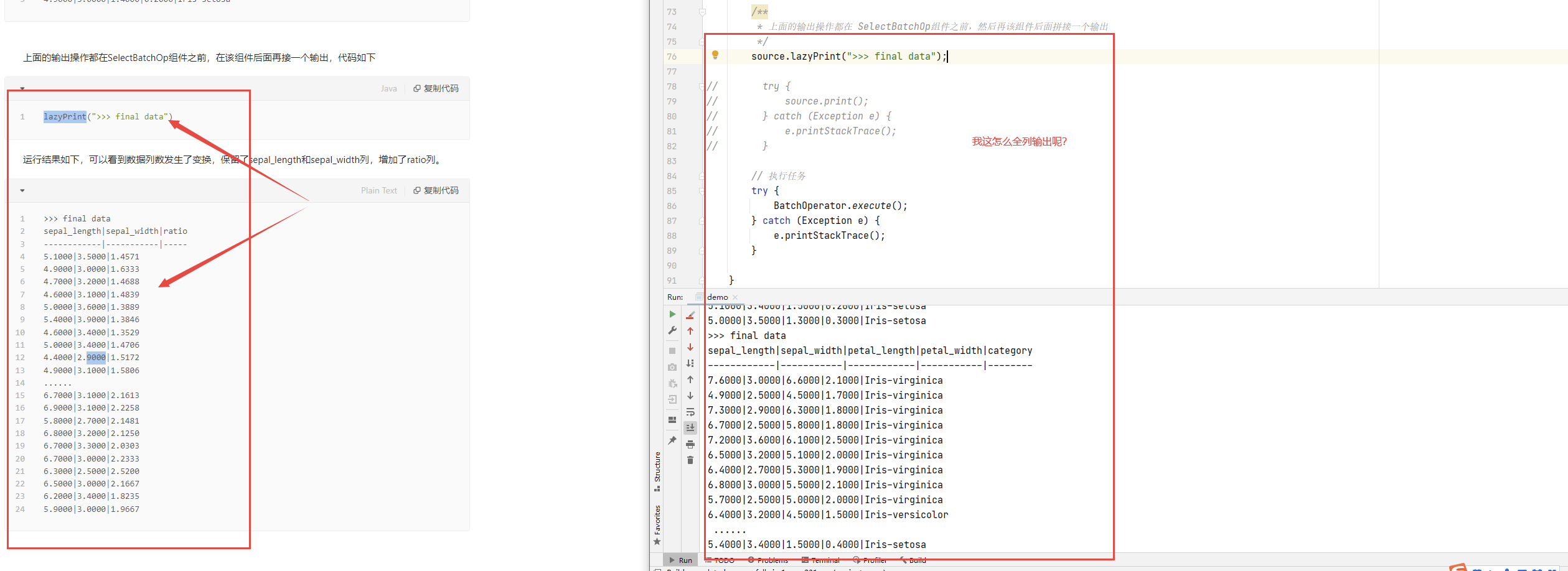
【答复】
使用如下代码,指定打印的行数为-1,即全部打印。
lazyPrint(-1, ">>> final data");
在教程中相关介绍如下:
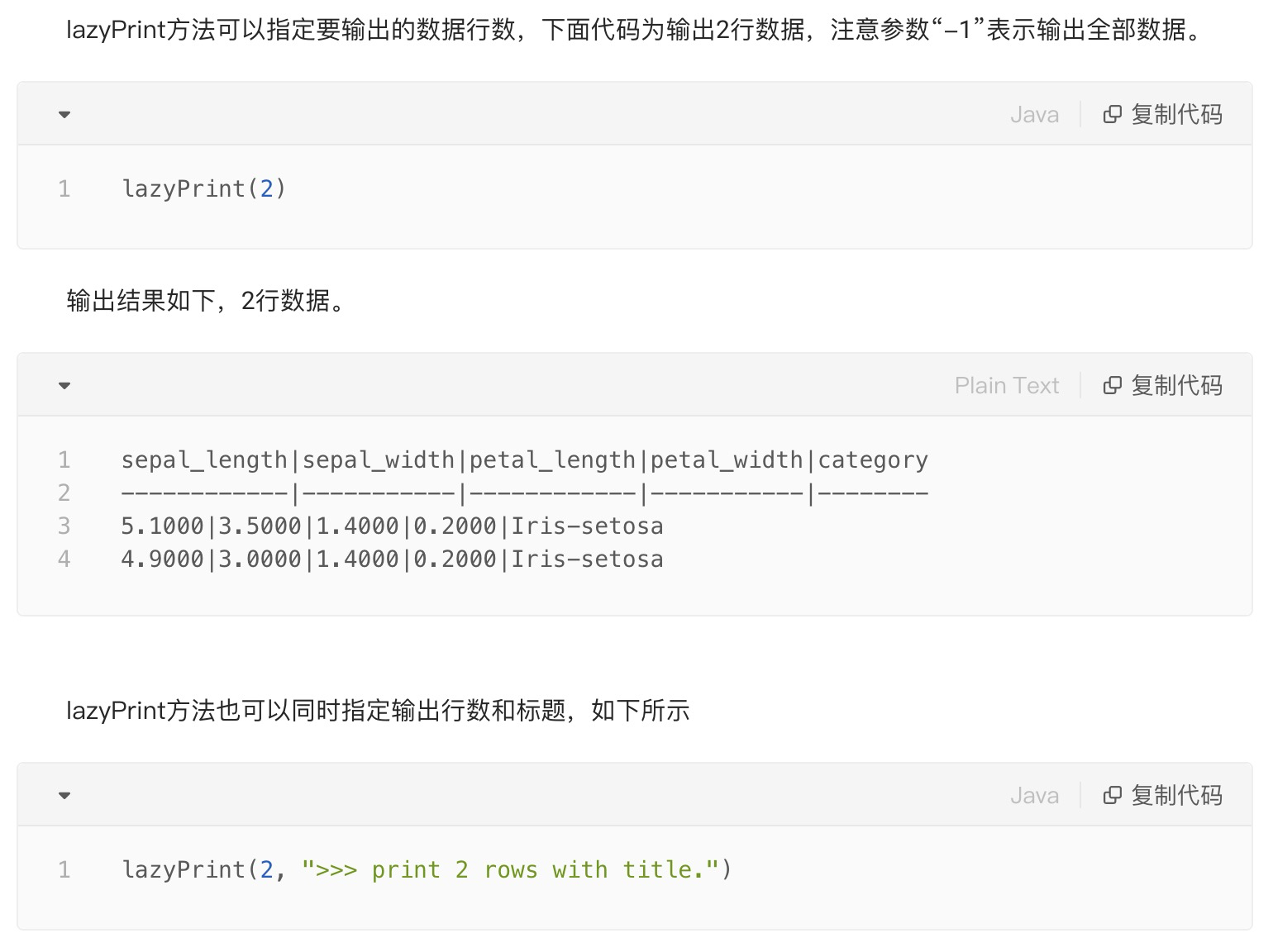
4、分类器的预测代码
【问题】
随机森林分类器预测代码是啥,这个示例好像只有训练

【答复】
这是Pipeline形式,包括了预测。参见教程2.4节 Pipeline与PipelineModel 和13.5节决策树与随机森林。
5、如何分别在隔离的集群进行训练和预测
【问题】
A 集群和B集群网络和数据都无法直接互通。能否在A集群训练模型,将训练好的模型导出成文件。将文件复制到B集群,然后包装成基于kafka的在线预测接口?
【答复】
该场景适合使用PipelineModel,参见教程1.5.4节的demo,关于Pipeline更多的内容参见2.4节 Pipeline与PipelineModel。
6、执行过程中返回状态信息
【问题】
BatchOperator.execute() 或者 StreamOperator.execute() 这种 execute 操作会把当前的程序阻塞起来。如果一个任务执行的时间特别长,有没有办法在 execute 执行的过程中返回一些状态呢?
【答复】
使用setPrintProcessInfo方法,会输出Alink组件运行过程中一些信息;用户也可以在代码中使用print语句,输出状态信息。setPrintProcessInfo方法的使用,可以参见教程第13.4节和第23.1.2节的例子。
Java代码:
AlinkGlobalConfiguration.setPrintProcessInfo(true);
Python代码:
AlinkGlobalConfiguration.setPrintProcessInfo(True)
7、支持特征向量吗?
【问题】
alink里面机器学习模型可以用向量数据去构建吗?
【答复】
可以的,Alink的大部分模型都支持setVectorCol方法,即可输入向量特征。
关于向量特征的预处理和建模,建议参考教程第8.8节 特征的多项式扩展;10.3节 离散特征转化;13.1.2节 稠密向量与稀疏向量;在第13.2节、13.3节、13.6节、14.5节、17.2.2节、19.1节中都有典型的应用。