第8章 线性二分类模型
勘误
1、在教程(Java版)的表8-7、教程(Python版)的表8-6中的PR曲线(如下面截图所示)的横纵坐标写反了。这是Alink旧版本的一个bug,在后面的版本中已经修复。读者现在运行示例代码可以得到正确的PR曲线图。
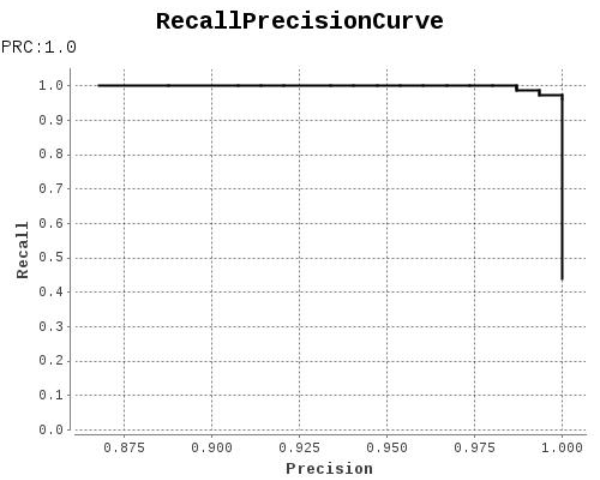
附书中PR(Precision Recall)曲线的定义如下,显然,图是横坐标是召回率Recall,纵坐标为准确率Precision。

答疑
1、特征列FeatureCols和向量列VectorCol的区别
【问题】
分类器的特征列FeatureCols和向量列VectorCol有什么区别吗?之间有什么关系?
【答复】
有两种常用的特征表示方式。一种是,每个特征对应数据表的一列,对应一个列名,通过指定列名集合的方式,即输入FeatureCols,确定使用哪些特征。另一种是,用一个向量表示所有的特征,Alink提供了特征向量的生成方式和常用操作,使用时输入特征向量所在的列名VectorCol即可。参数FeatureCols和VectorCol都不是必填参数,意味着用户可以选择使用那种特征表示方式,两种方式只填其一。
2、获取全部模型信息
【问题】
LR模型使用lazyPrintTrainInfo() 方法只能打印出部分特征的重要性,有没有对应的方法可以导出所有的内容呀~
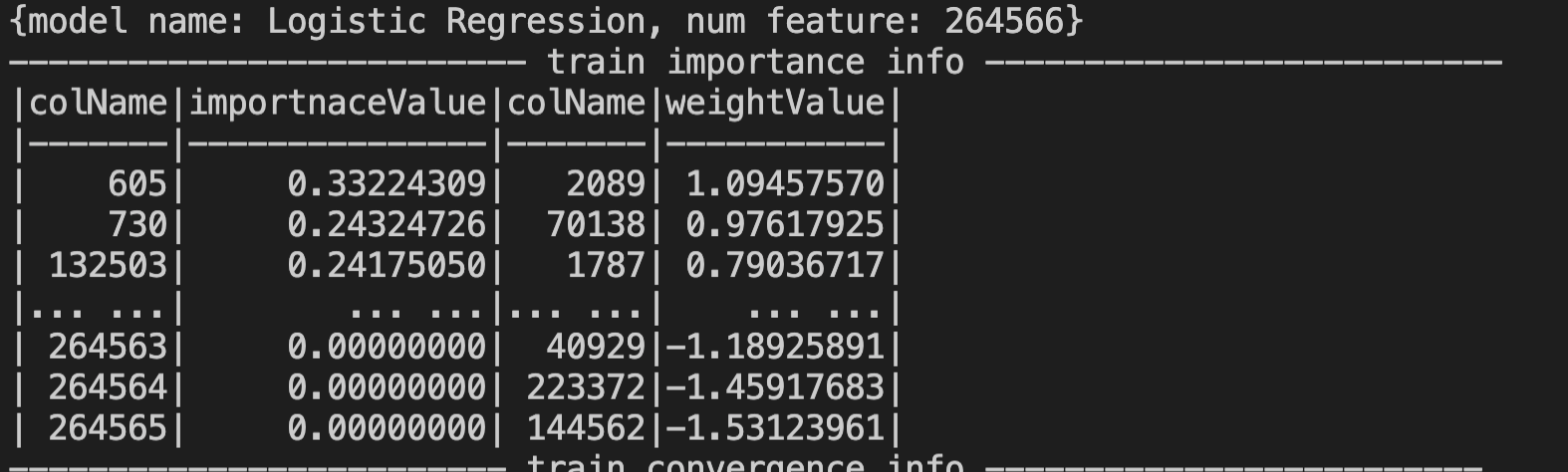
【答复】
可以使用lazyCollectModelInfo 这个函数,可以拿到完整的信息,然后自己可以打印里面的信息。贴一个例子,是C45算法的,LR可以类似获取,在 accept方法中写你的处理逻辑

3、逻辑回归里的样本加权参数
【问题】
逻辑回归里有一个参数:WeightCol,这个是做样本加权的吗?如果是的话,是在计算损失函数的时候进行加权的吗?
【答复】
是在计算损失函数的时候进行加权。在教程8.1.2节,当没有设置样本加权列时,会将各个样本的权重看作1,这样,经验风险(损失)为:

如果定义了样本加权列WeightCol,则每个样本 对应一个样本权重
对应一个样本权重 ,加权的经验风险(损失)为:
,加权的经验风险(损失)为:

4、predictionCol与predictionDetailCol
【问题】
我的训练模型就是TF-IDF + SVM的 二分类模型,但是用二分类的评估方法报错,感觉字段设置没问题啊,是不是用法不对。我改成多分类评估就可以
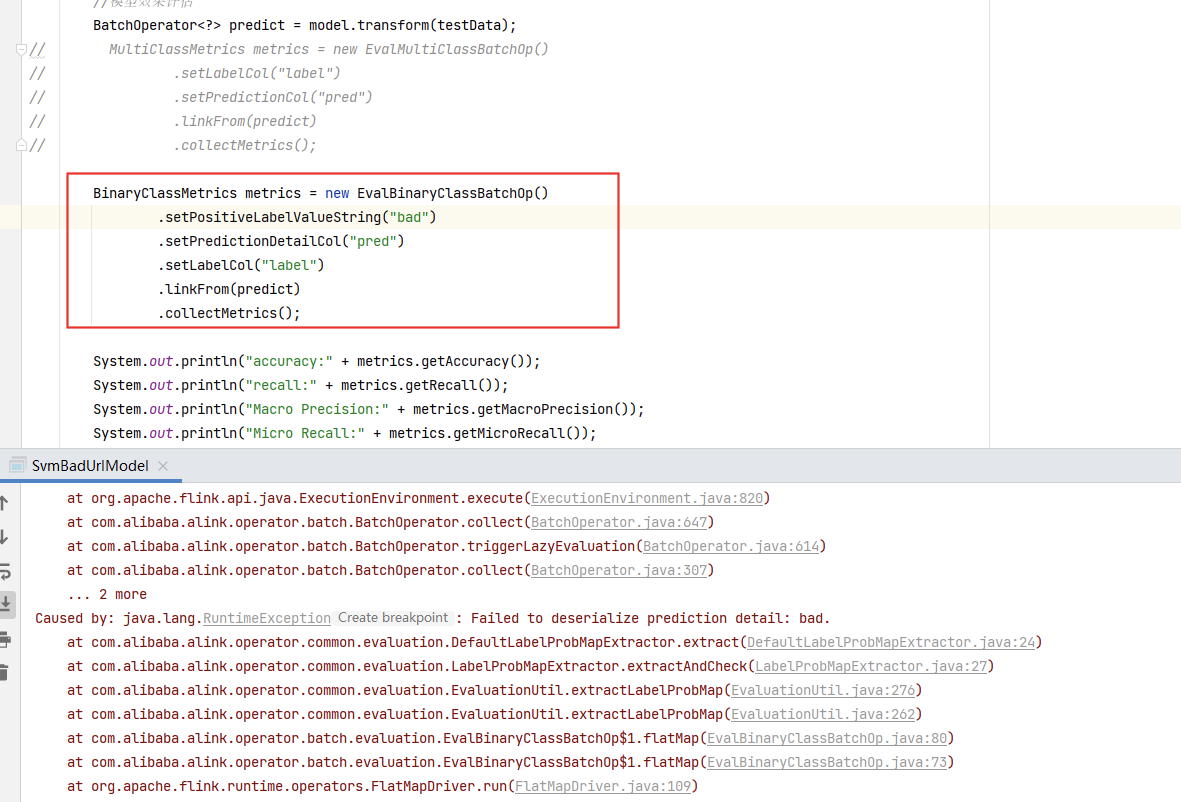
使用SVM组件的代码如下:
// 支持向量机模型
new LinearSvm()
.setVectorCol("featureVector")
.setLabelCol("label")
.setPredictionCol("pred")【答复】
问题在于二分类评估时,需要预测概率值,而预测概率值存在predictionDetailCol中,代码中只设定了PredictionCol,而没有输出predictionDetailCol。
参见教程 第8.5节( 逻辑回归模型) 中的介绍:预测组件需要指定预测结果列名,即参数 predictionCol,分类预测结果会被放在该列。另外,如果想要获取更多的信息,了解预测过程中对各分类情况的概率值,可以通过设置预测详情列名, 即参数predictionDetailCol 来完成。设置了该列名,预测结果数据集中就会有这样一列:该列为字符串类型值,给出了属于各分类值的概率,可用于二分类评估。
正确的组件参数设定如下:
new LinearSvm()
.setVectorCol("featureVector")
.setLabelCol("label")
.setPredictionCol("pred")
.setPredictionDetailCol("pred_info")BinaryClassMetrics metrics = new EvalBinaryClassBatchOp()
.setPositiveLabelValueString("bad")
.setPredictionDetailCol("pred_info")
.setLabelCol("label")
.linkFrom(predict)
.collectMetrics();