基于图算法实现金融风控
图算法一般被用来解决关系网状的业务场景。与常规的结构化数据不同,图算法需要把数据整理成首尾相连的关系图谱,更多的是考虑边和点的概念。这里提供了丰富的图算法组件,包括K-Core、最大联通子图、标签传播聚类等。
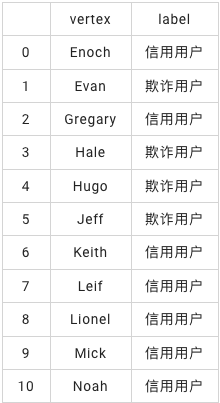
本示例是使用人物关系图数据,和少量标记用户数据,基于图算法实现金融风控。
导入 pyalink 包,并启用本地运行环境
在这个示例中,我们使用 useLocalEnv 在本地运行 Alink 作业,对于更大规模的数据,可以参考教程内容(https://www.yuque.com/pinshu/alink_tutorial/book_python_01_2_2),向大规模集群提交作业。
from pyalink.alink import * useLocalEnv(1)
数据准备
本示例需要两个数据集:人物关系图数据表和已知用户标签表(标记哪些用户是欺诈用户,哪些用户是信用用户)。
人物关系图数据
- 每两个人之间的连线表示两人有一定关系,可以是同事关系或者亲人关系等。
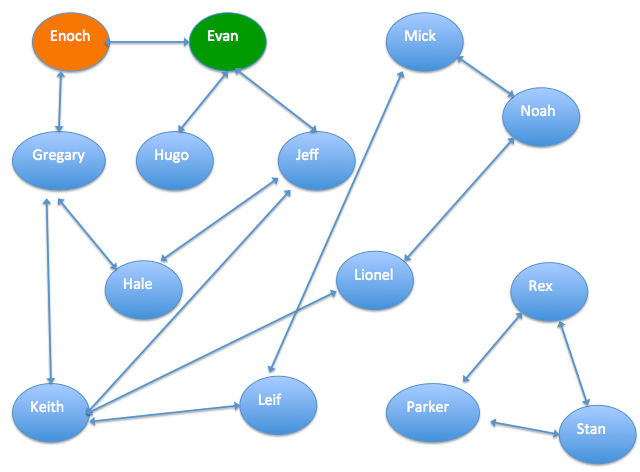
人物关系图数据定义
# Alink支持多种数据源, 包括MaxCompute表,OSS,Oracle,内存数据源等。这里使用了内存数据源。
import pandas as pd
df = pd.DataFrame([
["Enoch", "Evan", 10],
["Enoch", "Gregary", 2],
["Gregary", "Hale", 6],
["Evan", "Hugo", 2],
["Evan", "Jeff", 4],
["Gregary", "Keith", 7],
["Jeff", "Keith", 5],
["Hale", "Jeff", 11],
["Keith", "Leif", 3],
["Keith", "Lionel", 1],
["Leif", "Mick", 4],
["Mick", "Noah", 5],
["Lionel", "Noah", 5],
["Rex", "Parker", 3],
["Rex", "Stan", 4],
["Stan", "Parker", 5]
])
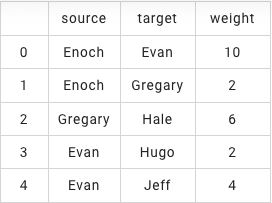
edges = BatchOperator.fromDataframe(df, schemaStr='source string, target string, weight double')查看人物关系表
edges.lazyPrint(5) BatchOperator.execute()
已知用户标签表
df_labeled_vertices = pd.DataFrame([
["Enoch", "信用用户", 1.0],
["Evan", "欺诈用户", 0.8]
])
labeled_vertices = BatchOperator.fromDataframe(df_labeled_vertices, schemaStr='vertices string, labels string, weight double')
labeled_vertices.print()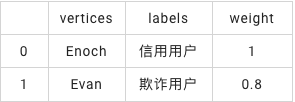
使用图算法判断用户是否是欺诈用户
分为三步,
第一步,最大联通子图
通过最大联通子图组件将数据中的群体分为两部分,并赋予group_id。然后通过filter和JOIN去除图中的无关联人员。
最大联通子图组件可以查找具有通联关系的最大集合,从而排除团队中与风控无关的人。
# 通过联通子图找到无关人员
connected_components = edges\
.link(
ConnectedComponentsBatchOp()\
.setEdgeSourceCol("source")\
.setEdgeTargetCol("target")\
)\
.lazyPrint(title="【连通子图】")
BatchOperator.execute()【连通子图】
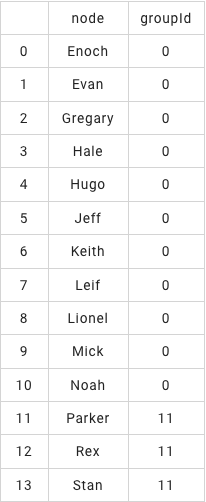
画成下图:
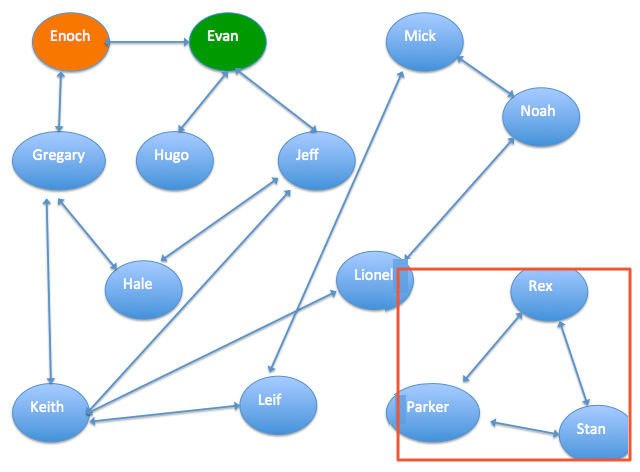
如上图所示,结果有两组,groupId=0和groupId=11,可以看出groupId=11中没有已标记的欺诈用户和诚信用户,因此认为groupId=11是无关联人员,需要去掉。
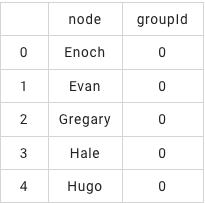
# 过滤groupId=0的用户
selected_nodes = connected_components\
.filter("groupId=0") \
.lazyPrint(5, title="【选择 group 0】")
BatchOperator.execute()【选择 group 0】
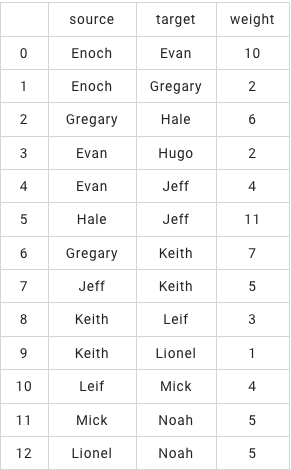
# 使用Join, 去掉无关人员
join1 = JoinBatchOp()\
.setJoinPredicate("source=node")\
.setSelectClause("source, target, weight")\
.linkFrom(edges, selected_nodes)
filtered_edges = JoinBatchOp()\
.setJoinPredicate("target=node")\
.setSelectClause("source, target, weight")\
.linkFrom(join1, selected_nodes)\
.lazyPrint(title="【过滤后的边】")
BatchOperator.execute()【过滤后的边】
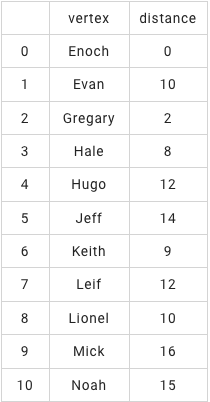
第二步,探查每个人的一度人脉及二度人脉等关系
单元最短路径组件的输出结果中,distance表示Enoch通过几个人可以联络到目标人
# 指定source(源头) = 'Enoch'
filtered_edges.link(\
SingleSourceShortestPathBatchOp()\
.setIsUndirectedGraph(True)\
.setEdgeSourceCol("source")\
.setEdgeTargetCol("target")\
.setEdgeWeightCol("weight")\
.setSourcePoint("Enoch")\
)\
.lazyPrint(title="【单源最短路径】")
BatchOperator.execute()【单源最短路径】
第三步,使用标签传播确定未标记点的标签
标签传播分类为半监督的分类算法,原理为用已标记节点的标签信息去预测未标记节点的标签信息。
在算法执行过程中,每个节点的标签按相似度传播给相邻节点,在节点传播的每一步,每个节点根据相邻节点的标签来更新自己的标签, 与该节点相似度越大,其相邻节点对其标注的影响权值越大,相似节点的标签越趋于一致,其标签就越容易传播。 在标签传播过程中,保持已标注数据的标签不变,使其像一个源头把标签传向未标注数据。
最终,当迭代过程结束时,相似节点的概率分布也趋于相似,可以划分到同一个类别中,从而完成标签传播过程
# 标签传播算法
CommunityDetectionClassifyBatchOp()\
.setIsUndirectedGraph(True)\
.setEdgeSourceCol("source")\
.setEdgeTargetCol("target")\
.setEdgeWeightCol("weight")\
.setVertexCol("vertices")\
.setVertexLabelCol("labels")\
.linkFrom(filtered_edges, labeled_vertices)\
.lazyPrint(title="【标签传播--过滤的节点】")
BatchOperator.execute()【标签传播--过滤的节点】