GBDT+FM 一体化模型训练及预测
GBDT+FM 模型是由 Gbdt+LR 延伸出来的模型。该模型利用GBDT自动进行特征筛选和组合,进而生成新的离散特征向量,再把该特征向量当做 FM 模型的输入,来产生最后的预测结果。该模型能够综合利用用户、物品和上下文等多种不同的特征,生成较为全面的推荐,在CTR点击率预估场景下使用较为广泛。
本文将介绍如何使用 Alink 快速的构建 Gbdt+FM 模型,并且会介绍如何方便的将建立的模型部署成服务。
数据准备
Adult 数据来源 https://archive.ics.uci.edu/ml/datasets/Adult
算法相关文档:https://alinklab.cn/manual/csvsourcebatchop.html
Adult数据集(即“人口普查收入”数据集),由美国人口普查数据集库 抽取而来,其中共包含48842条记录,年收入大于50k美元的占比23.93%,年收入小于50k美元的占比76.07%,并且已经划分为训练数据32561条和测试数据16281条。 该数据集类变量为年收入是否超过50k美元,属性变量包括年龄、工种、学历、职业等 14类重要信息,其中有8类属于类别离散型变量,另外6类属于数值连续型变量。该数据集是一个分类数据集,用来预测年收入是否超过50k美元。
PATH = "https://alink-test-data.oss-cn-hangzhou.aliyuncs.com/"
TRAIN_FILE = "adult_train.csv"
TEST_FILE = "adult_test.csv"
SCHEMA_STRING = "age bigint, workclass string, fnlwgt bigint, education string, education_num bigint,"\
+ " marital_status string, occupation string, relationship string, race string, sex string, "\
+ "capital_gain bigint, capital_loss bigint, hours_per_week bigint, native_country string, label string"
trainData = CsvSourceBatchOp() \
.setFilePath(PATH + TRAIN_FILE) \
.setFieldDelimiter(",") \
.setSchemaStr(SCHEMA_STRING)
testData = CsvSourceBatchOp() \
.setFilePath(PATH + TEST_FILE) \
.setFieldDelimiter(",") \
.setSchemaStr(SCHEMA_STRING)
trainData.lazyPrint(5)
BatchOperator.execute()运行结果为:
训练模型
算法相关文档:
我们通过将 GbdtEncoder 和 FM 这两个算子放到一个Pipeline的方式完成模型的一体化训练。这里是用GbdtEncoder对输入的数据进行编码,并将编码的结果输送给FM进行训练。最终我们得到一个pipeline model,这个模型可以用来对数据进行推理,也可以部署成服务。
featureCols = ["age", "fnlwgt", "education_num", "capital_gain",
"capital_loss", "hours_per_week", "workclass", "education", "marital_status", "occupation",
"relationship", "race", "sex", "native_country"]
numericalCols = ["age", "fnlwgt", "education_num", "capital_gain",
"capital_loss", "hours_per_week"]
label = "label"
vecCol = "vec"
gbdtFmPipe = Pipeline() \
.add(
GbdtEncoder()\
.setLabelCol(label)\
.setFeatureCols(featureCols)\
.setReservedCols([label])\
.setPredictionCol(vecCol))\
.add(
FmClassifier() \
.setVectorCol(vecCol) \
.setLabelCol(label) \
.setReservedCols([label]) \
.setPredictionDetailCol("detail") \
.setPredictionCol("pred"))
model = gbdtFmPipe.fit(trainData)模型评估
算法相关文档:
- https://alinklab.cn/manual/evalbinaryclassbatchop.html
- https://alinklab.cn/manual/jsonvaluebatchop.html
模型评估阶段,我们先试用上面训练好的模型对testData进行推理,然后用评估组件EvalBinaryClassBatchOp对推理结果进行评估,最后使用JsonValueBatchOp组件完成评估结果的抽取。
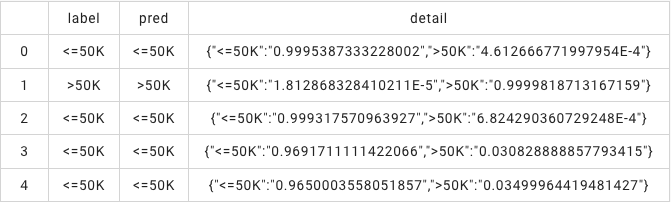
result = model.transform(testData)
result.lazyPrint(5)
EvalBinaryClassBatchOp() \
.setPredictionDetailCol("detail").setLabelCol(label).linkFrom(result) \
.link(JsonValueBatchOp().setSelectedCol("Data") \
.setReservedCols([]) \
.setOutputCols(["Accuracy", "AUC", "ConfusionMatrix"]) \
.setJsonPath(["$.Accuracy", "$.AUC", "ConfusionMatrix"])).print()运行结果为:

与 Gbdt+LR 效果对比
参考通过对比可以看到,Gbdt+FM 的效果要比 Gbdt+LR 好一些,对于同一个数据,AUC 大概高0.7个百分点。
gbdtLrPipe = Pipeline() \
.add(
GbdtEncoder()\
.setLabelCol(label)\
.setFeatureCols(featureCols)\
.setReservedCols([label])\
.setPredictionCol(vecCol))\
.add(
LogisticRegression() \
.setVectorCol(vecCol) \
.setLabelCol(label) \
.setReservedCols([label]) \
.setPredictionDetailCol("detail") \
.setPredictionCol("pred"))
lrModel = gbdtLrPipe.fit(trainData)
resultLr = lrModel.transform(testData)
resultFm = model.transform(testData)
EvalBinaryClassBatchOp() \
.setPredictionDetailCol("detail").setLabelCol(label).linkFrom(resultLr) \
.link(JsonValueBatchOp().setSelectedCol("Data") \
.setReservedCols([]) \
.setOutputCols(["Accuracy", "AUC", "ConfusionMatrix"]) \
.setJsonPath(["$.Accuracy", "$.AUC", "ConfusionMatrix"])).print()
EvalBinaryClassBatchOp() \
.setPredictionDetailCol("detail").setLabelCol(label).linkFrom(resultFm) \
.link(JsonValueBatchOp().setSelectedCol("Data") \
.setReservedCols([]) \
.setOutputCols(["Accuracy", "AUC", "ConfusionMatrix"]) \
.setJsonPath(["$.Accuracy", "$.AUC", "ConfusionMatrix"])).print()
模型写出
算法相关文档:
模型写出阶段,我们使用AkSinkBatchOp将模型写出到文件系统,这里的文件系统可以是本地文件系统(如代码所示),也可以时网络文件系统(比如OSS),可以通过代码:
fs = OssFileSystem("3.4.1", "oss-cn-hangzhou-zmf.aliyuncs.com", "name", "************", "**********")
filePath = FilePath("/model/gbdt_fm_model.ak", fs)完成网络文件系统路径的构建,将这个路径以参数的方式塞给AkSinkBatchOp组件:
AkSinkBatchOp().setFilePath(filePath).setOverwriteSink(True)
便可以完成将模型写出待网络文件系统的目的。
modelData = model.save();
filePath = "/tmp/gbdt_fm_model.ak"
# 可以将模型文件写出到OSS,这样可以直接部署到EAS,需要一个OSS的idkey。此处直接写出到/tmp 目录下
# fs = OssFileSystem("3.4.1", "oss-cn-hangzhou-zmf.aliyuncs.com", "name", "************", "**********")
# filePath = FilePath("/model/gbdt_fm_model.ak", fs)
modelData.link(AkSinkBatchOp().setFilePath(filePath).setOverwriteSink(True));
BatchOperator.execute();加载模型并推理
这里加载模型的路径和模型写出时一样,可以是本地文件系统(如代码所示),也可以时网络文件系统(比如OSS)。
model = PipelineModel.load(filePath) result = model.transform(testData).lazyPrint(5) BatchOperator.execute()
运行结果为: