第21章 文本分析
答疑
1、IDF的计算问题
【问题】
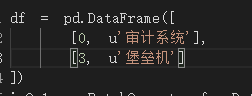
idf计算是不是错了?
idf计算结果
用底数为e或2都不是这个结果
|

【答复】
实际应用时,对这个公式进行了调整,
double idf = Math.log((1.0 + docCnt) / (1.0 + df));
对于你的例子
System.out.println(Math.log((1.0+2)/(1.0+1)));
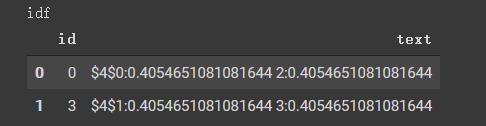
结果正好为 0.4054651081081644
2、中、英文分词的问题
【问题】
问下 Segment对英文分词不起作用吗?
【答复】
是的,Segment仅支持中文分词,详见教程21.2.1节 中文分词。英文分词请参考教程21.2.2节 Tokenizer和RegexTokenizer
3、英文的切分
【问题】
对英文进行切分,比如thatisanenglishbook 分出 that is an english book,或者baidu ba ai id du bai aid idu 这样的
【答复】
第一种方式做不到,但是第二种方式,可以使用先有组件实现。需要用到教程23.3节中的NGram组件;教程21.2.2节中的RegexTokenizer,具体代码如下:
new MemSourceBatchOp(new Object[] {"example"}, "txt")
.link(
new RegexTokenizerBatchOp()
.setGaps(false)
.setPattern(".")
.setSelectedCol("txt")
)
.link(
new NGramBatchOp()
.setSelectedCol("txt")
.setOutputCol("txt_2")
.setN(2)
)
.link(
new NGramBatchOp()
.setSelectedCol("txt")
.setOutputCol("txt_3")
.setN(3)
)
.print();运行结果为:
txt|txt_2|txt_3 ---|-----|----- e x a m p l e|e_x x_a a_m m_p p_l l_e|e_x_a x_a_m a_m_p m_p_l p_l_e
4、TF_IDF
【问题】
请问下alink里面有没有tf_idf这个模型可以用?
【答复】
有,参见教程21.4节 单词的区分度;在21.5.2节 有使用TF_IDF提取关键词的例子。