- Alink权威指南:机器学习实例入门(Python版)
- Alink教程(Python版)目录
- Alink教程(Python版)代码的运行攻略
- Alink教程(Python版)的数据和资料链接
- 第1章 Alink快速上手
- 第1.1节 Alink是什么
- 第1.2节 免费下载、安装
- 第1.2.1节 PyAlink快速开始
- 第1.2.1.1节 PyAlink安装准备——MacOS
- 第1.2.1.2节 PyAlink安装准备——阿里云服务器
- 第1.2.1.3节 如何安装最新版本PyAlink?
- 第1.2.1.4节 PyAlink的版本查询、卸载旧版本
- 第1.2.2节 在 Flink 集群上运行 PyAlink 任务
- 第1.3节 Alink的功能
- 第1.4节 关于数据和代码
- 第1.5节 简单示例
- 第2章 系统概况与核心概念
- 第2.1节 基本概念
- 第2.2节 批式任务与流式任务
- 第2.3节 Alink=A+link
- 第2.4节 Pipeline与PipelineModel
- 第2.5节 触发Alink任务的执行
- 第2.5.1节 批式任务打印输出中间结果
- 第2.6节 模型信息显示
- 第2.7节 文件系统与数据库
- 第2.8节 Schema String
- 第3章 文件系统与数据文件
- 第3.2.4节 读取Parquet文件格式数据
- 第3.2.5节 定时输出流式数据
- 第3.2.6节 读取分区格式数据
- 第4章 数据库与数据表
- 第4.5节 Alink连接Kafka数据源
- 第5章 支持Flink SQL
- 第5.3.4节 Flink与Alink的数据转换
- 第6章 用户定义函数(UDF/UDTF)
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第10章 特征的转化
- 第11章 构造新特征
- 第12章 从二分类到多分类
- 第13章 常用的多分类算法
- 第14章 在线学习
- 第15章 回归的由来
- 第16章 常用的回归算法
- 第17章 常用的聚类算法
- 第18章 批式与流式聚类
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第22章 单词向量化
- 第23章 情感分析
- 第23.5节 中文情感分析示例
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 第25.1节 深度学习组件简介
- 第25.1.1节 深度学习功能概览
- 第25.1.2节 KerasSequential组件
- 第25.1.3节 深度学习相关插件的下载
- 第25.2节 手写识别MNIST
- 第25.3节 深度回归算法
- 第25.4节 运行TensorFlow模型
- 第25.5节 运行PyTorch模型
- 第25.6节 使用自定义 TensorFlow 脚本
- 第25.7节 运行ONNX模型
- 第26章 图像识别
- 第26.1节 数据准备
- 第26.2节 构造二分类模型
- 第26.3节 使用TF Hub模型
- 第1章 Alink快速上手
- 在Flink集群部署Alink
- 在易用性方面的小技巧
- 流式组件输出数据的显示(基于Jupyter环境)
- Alink插件下载器
- 第2章 系统概况与核心概念
- Failed to load BLAS警告——Mac OS上解决方法
- 在Linux,Mac下定时执行Alink任务
- 第3章 文件系统与数据文件
- 第4章 数据库与数据表
- Catalog中设置数据库分区【Alink使用技巧】
- 在MacOS上搭建Kafka
- 在Windows上搭建Kafka
- 第5章 支持Flink SQL
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第11章 构造新特征
- GBDT+LR 一体化模型训练与预测
- GBDT+FM 一体化模型训练及预测
- 第13章 常用的多分类算法
- 第14章 在线学习 Ftrl Demo
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 基于图算法实现金融风控
- 如何使用Alink时间序列算法?
- 如何使用Alink窗口特征生成?
第1.5节 简单示例
这里将通过几个简单的Alink示例,让读者留下一个初步的Alink印象。
1.5.1 数据的读/写与显示
我们以常用的鸢尾花(iris)数据集为例,演示一下如何读取数据。
数据下载链接:http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
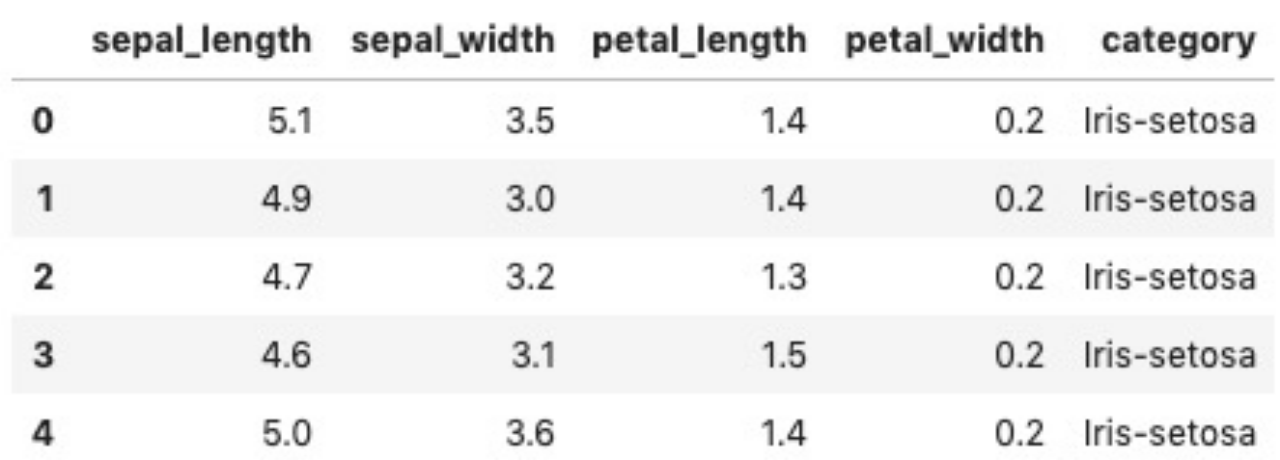
Alink的CSV格式数据源读取组件,不但可以读取本地文件,还可以直接读取网络文件;在该组件读取文件的时候需要指定各列数据的名称和类型。下面是具体的代码。在此,读取出数据后,选择前5条数据进行打印输出:
source = CsvSourceBatchOp()\
.setFilePath("http://archive.ics.uci.edu/ml/machine-learning-databases"
+ "/iris/iris.data")\
.setSchemaStr("sepal_length double, sepal_width double, petal_length double, "
+ "petal_width double, category string")
source.firstN(5).print();运行结果如下:
下一步,我们对数据进行采样,采样数为10条。然后连接到CSV格式输出组件CsvSinkBatchOp,并设置相应的输出路径。可以设置覆盖写参数为true。
source.sampleWithSize(10)\
.link(
CsvSinkBatchOp()\
.setFilePath(DATA_DIR + "iris_10.data")\
.setOverwriteSink(True)
)
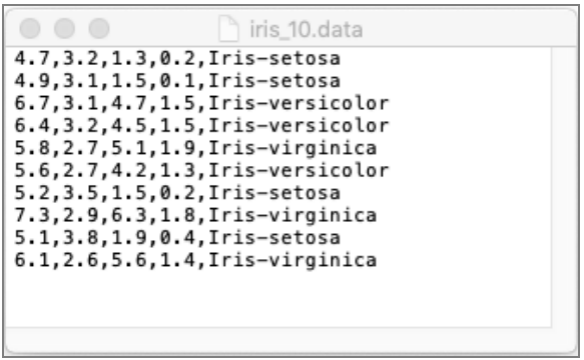
BatchOperator.execute();采样出来的数据被保存到文件iris_10.data。使用文本编辑器显示这些数据,如下图所示,正好10行,数据间使用逗号进行分隔,这是标准的CSV格式。
1.5.2 批式训练和批式预测
从本节开始,我们以预测某电商平台“双11”的成交总额(GMV,Gross Merchandise Volume)为例,演示各种操作。
我们很容易查到某电商平台历年“双11”的成交总额,下面是其2009—2017年的记录,成交总额的单位为万亿元,左边年份列记为x,右边成交总额列记为gmv。我们可以使用Python中常用的构造DataFrame的方法,然后使用fromDataframe方法,将DataFrame格式的数据转换为Alink批式数据。(注:在本书的7.6节中,有关于Python数组、DataFrame和Alink批式数据互相转换的介绍。)
df = pd.DataFrame(
[
[2009, 0.5],
[2010, 9.36],
[2011, 52.0],
[2012, 191.0],
[2013, 350.0],
[2014, 571.0],
[2015, 912.0],
[2016, 1207.0],
[2017, 1682.0]
]
)
train_set = BatchOperator.fromDataframe(df, schemaStr='x int, gmv double')
df_2 = pd.DataFrame(
[
[2018],
[2019]
]
)
pred_set = BatchOperator.fromDataframe(df_2, schemaStr='x int')我们需要对这些数据进行建模,从而预测该电商平台2018年和2019年的值。由于2018年和2019年已经过去,我们知道实际的数值:2018年该电商平台的成交总额为2135亿元,2019年该电商平台的成交总额为2684亿元。
从年份和成交总额的数据上看,二者显然不成线性关系,这就需要构造新的特征,更好地拟合历史数据,进行预测。我们可以定义x的平方为新的特征,这样就相当于计算gmv与关于x的二次多项式之间的关系。
train_set = train_set.select("x, x*x AS x2, gmv");
trainer = LinearRegTrainBatchOp()\
.setFeatureCols(["x", "x2"])\
.setLabelCol("gmv")
train_set.link(trainer);
trainer.link(
AkSinkBatchOp()\
.setFilePath(DATA_DIR + "gmv_reg.model")\
.setOverwriteSink(True)
)
BatchOperator.execute();需要说明的是:
- train_set.select("x, x*x AS x2, gmv")实际上是对数据表train_set执行SQL语句“SELECT x, x*x AS x2, gmv FROM train_set”。更详细的内容,读者可以参阅本书第5章有关SQL语句的具体操作。
- 定义LinearRegTrainBatchOp类型的组件trainer,即训练器,并设置其特征参数和标签参数。
- train_set.link(trainer)可将训练数据与训练器连接(link)起来。
- 随后,训练器trainer的输出为模型。将训练器trainer连接到数据导出组件AlinkFileSinkBatchOp,就会将模型数据导出到文件gmv_reg.model。并且由于设置了setOverwriteSink(true),因此如果目标文件存在,则会将其覆盖。
- 最后,调用BatchOperator.execute(),执行批式任务。
运行结束后,可以看到生成了gmv_reg.model文件。下面,我们导入此模型,并进行批式预测:
lr_model = AkSourceBatchOp().setFilePath(DATA_DIR + "gmv_reg.model")
pred_set = pred_set.select("x, x*x AS x2")
predictor = LinearRegPredictBatchOp().setPredictionCol("pred")
predictor.linkFrom(lr_model, pred_set).print();预测流程分为如下几步:
(1)通过AlinkFileSourceBatchOp读取文件gmv_reg.model,得到模型数据,并记为lr_model。
(2)预测的原始数据只有一列x,需要执行SQL SELECT方案,生成新的特征x2。
(3)定义线性回归的批式预测组件(LinearRegPredictBatchOp)为predictor,指定输出结果列的名称。
(4)将这些组件组合为预测流程。因为predictor需要模型数据及预测特征数据,所以使用linkFrom方法,同时连接两个上游组件。之后链式调用print方法,输出预测结果。注意:在批式场景中的print方法本身就会触发批式任务执行,这里就不用再调用BatchOperator.execute()了。
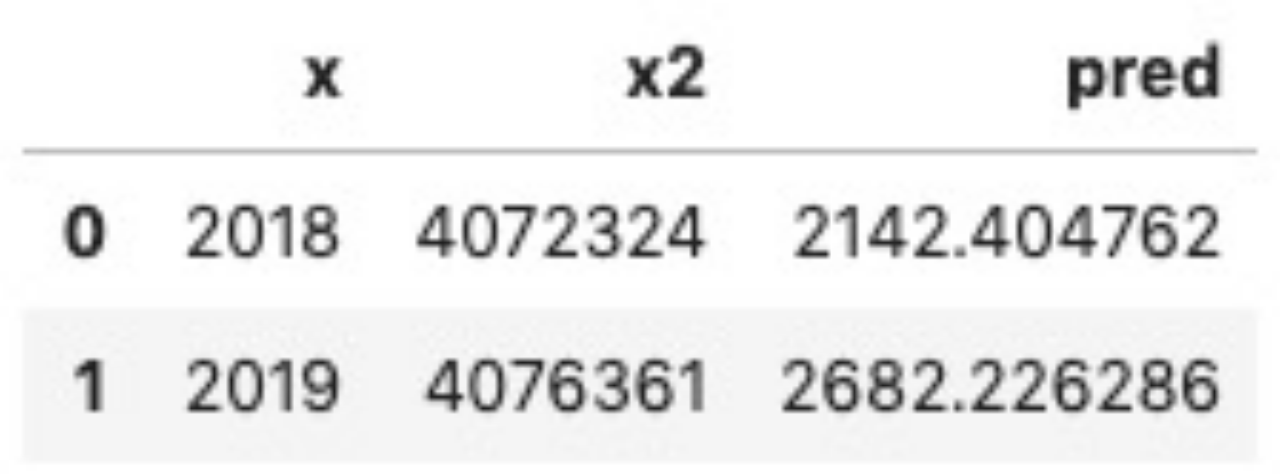
下图为模型预测结果,其最后一列为预测的成交额(单位:亿元)。我们对比前面提到的实际数值(2018年该电商平台的成交总额为2135亿元,2019年该电商平台的成交总额为2684亿元),可以发现该预测结果与实际数值非常接近。
1.5.3 流式处理和流式预测
前面介绍了批式模型训练,以及针对批式数据的预测。在实际的场景中,需要预测的数据常常以流的方式陆续到来,因此需要随时进行预测,即进行流式预测。
我们还是以某电商平台“双11”的成交总额预测为例,演示一个流式预测的简单场景:预测模型已经通过批式训练的方式生成,使用这个固定的预测模型,构建流式任务,预测流式数据。
Alink批式任务的代码与流式任务的代码很相似,将批式组件的名称后缀“BatchOp”改为“StreamOp”即可,参数基本不用调整;在一些使用方式上需要进行微调。流式预测的代码如下:
pred_set = StreamOperator.fromDataframe(df_2, schemaStr='x int')
lr_model = AkSourceBatchOp().setFilePath(DATA_DIR + "gmv_reg.model")
predictor = LinearRegPredictStreamOp(lr_model).setPredictionCol("pred")
pred_set\
.select("x, x*x AS x2")\
.link(predictor)\
.print()
StreamOperator.execute()可以对比批式预测的代码,理解流式预测的代码:
(1)在数据源获取方面,通过内存数据构造出一个流式数据源。这里的流式组件MemSourceStreamOp与前面的批式组件MemSourceBatchOp只有名称有区别,组件参数的设置类似。这就为我们进行流式操作和批式操作的互相转换提供了方便。
(2)因为使用批式的模型,这里还是通过AlinkFileSourceBatchOp读取文件gmv_reg.model,得到模型数据,并记为lr_model。
(3)定义线性回归的流式预测组件(LinearRegPredictStreamOp)为predictor,指定输出结果列的名称。注意:因为流式任务的流程中无法接入批式的数据,所以将批式模型数据lr_model作为LinearRegPredictStreamOp构造函数的参数传入。在流式任务执行前,会先完成批式模型数据的导入。
(4)组装预测流程。由于流式预测组件predictor已经在构造函数中导入了模型数据,因此只需连入一个流式预测数据即可,不要使用linkFrom方法。整个流程可以写得更简单,可直接把预测数据作为源头,接入流式SQL SELECT操作,生成x2(注意这里代码的写法,与批式调用时完全一致),然后连接流式预测组件predictor,并对预测结果进行打印。
(5)调用StreamOperator.execute(),执行流式任务。
流式预测结果,如下图所示,其与批式预测的结果完全相同。

注意:Alink在Jupyter上的流式数据的显示,采用时间窗口刷新的方式。如果数据流结束,则输出结果停留在最近显示的内容上;图上方的一串输出字符,就对应着流式数据显示的时间窗口信息。
1.5.4 定义Pipeline,简化操作
前面介绍了Alink在批式模型训练、批式预测和流式预测中的例子,可以看到这三个流程中都涉及两个步骤(使用SQL SELECT构造新的特征项,以及线性回归的训练或者预测),因此,可以对该功能进行抽象,形成Pipeline(管道)。其具体概念和用法在本书后面会介绍,这里就不展开说明了。这里只是通过示例,让读者有一个初步的印象:可以通过Pipeline简化操作。
示例代码如下:
train_set = BatchOperator.fromDataframe(df, schemaStr='x int, gmv double')
pipeline = Pipeline()\
.add(
Select().setClause("*, x*x AS x2")
)\
.add(
LinearRegression()\
.setFeatureCols(["x", "x2"])\
.setLabelCol("gmv")\
.setPredictionCol("pred")
)
pipeline.fit(train_set).save(DATA_DIR + "gmv_pipeline.model")
BatchOperator.execute()这段代码由四部分构成:
- 训练数据train_set生成的代码在前面出现过,这里不再重复。
- 核心为Pipeline的构成,其需要以下两个操作:
- Select
设置了SQL子语句“*, x*x AS x2”。注意第一个字符为“*”,因此会匹配输入数据表中出现的所有列。因为在批式训练场景中,输入的列为“x, gmv”,而在预测场景中输入的只有一列“x”,所以使用“*”会同时适用这两个场景。 - LinearRegression
设置了训练时需要的参数FeatureCols和LabelCol,也设置了预测时需要的PredictionCol。
- 有了Pipeline的定义后,对训练数据执行fit方法,就会得到PipelineModel(管道模型)。可以直接使用PipelineModel;也可选择保存PipelineModel,后面用在不同场景中。Alink提供了简单的保存PipelineModel的方法,提供文件路径,运行save方法即可。注意,save方法将PipelineModel对应的模型连接到了sink组件,还需要等到执行BatchOperator.execute()时,才会真正写出模型。
- 最后使用BatchOperator.execute(),执行批式任务。
下面我们将通过读取模型文件gmv_pipeline.model,得到PipelineModel,并使用其transform方法,对批式数据和流式数据进行预测。
读取模型文件,得到PipelineModel的代码很简单:
pipelineModel = PipelineModel.load(DATA_DIR + "gmv_pipeline.model")
对于批式数据的预测代码如下:
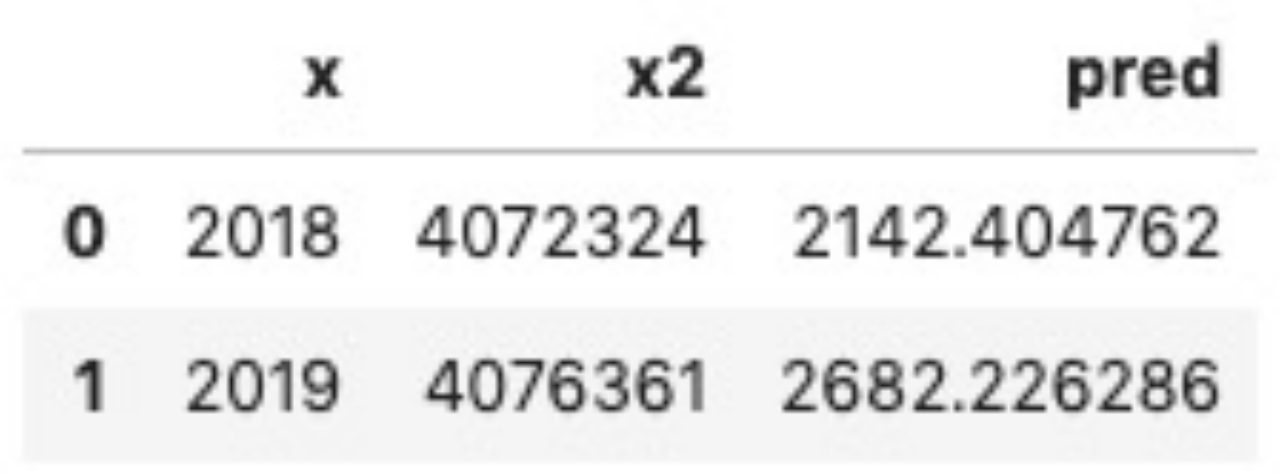
pred_batch = BatchOperator.fromDataframe(df_2, schemaStr='x int') pipelineModel.transform(pred_batch).print()
结果如下图所示:
对于流式数据的预测代码如下,我们看到pipelineModel对于批式数据和流式数据处理所用的方法名称都是一样的,使用方式也是一样的;但transform方法的输出结果究竟是批式的还是流式的,取决于输入数据是批式的还是流式的:
pred_stream = StreamOperator.fromDataframe(df_2, schemaStr='x int') pipelineModel.transform(pred_stream).print() StreamOperator.execute()
使用Pipeline方式,流式预测的结果如下图所示,与批式预测的结果相同。

1.5.5 嵌入预测服务系统
除了使用Alink算法组件直接对批式的数据或者流式的数据进行预测,用户也希望我们能提供SDK的方式,即,由参数或模型数据直接构建一个本地的Java实例,可以对单条数据进行预测,我们称之为LocalPredictor。如此一来,预测不再必须由Flink任务完成,而可以嵌入提供RestAPI的预测服务系统中,或者嵌入用户的业务系统里。
有了存储好的PipelineModel模型,可以直接使用LocalPredictor的构造函数来构建实例。构造函数需要两个参数,一个是PipelineModel模型文件的路径,另一个是所要预测数据的各数据列名称和类型,即输入一个Alink Schema String格式(详见2.8节的内容)的参数。这里的参数为"x int",表示输入的预测数据只有1列,名称为x,类型为整型。具体代码如下:
predictor = LocalPredictor(DATA_DIR + "gmv_pipeline.model", "x int")
LocalPredictor输入的预测数据是Row格式的,输出的预测结果也是Row格式的。Row格式本身并没有列名和类型的定义,需要通过在构造函数中输入预测数据的Schema来获取预测数据各数据列的名称和类型;LocalPredictor可以根据PipelineModel模型的计算过程,推导出预测结果的Schema(结果数据列名称及类型)。对于我们刚构建的localPredictor,使用getOutputSchema方法获取Schema信息并打印显示Schema信息,具体代码如下:
print(predictor.getOutputColNames());
运行结果如下:
['x', 'x2', 'pred']
可以看出,LocalPredictor的预测结果与批式和流式预测结果一样,其预测输出共3列,最关键的分类预测结果列“pred”在最后。
LocalPredictor使用map方法进行预测,具体代码如下:
for x in [2018, 2019] :
print(predictor.map([x]))计算结果如下:
[2018 4072324 2142.404761955142] [2019 4076361 2682.2262857556343]
最右面的数值是预测结果,对其保留小数点后6位有效数字,得到的结果与前面批式/流式任务计算的结果相同。