如何使用Alink时间序列算法?
时间序列算法在实际问题中使用的越来越多,Alink提供了多种时间序列算法,既可以用在批数据上,也可以用在流式数据上。可以使单变量,也可以是多元变量。支持算法如下图,算法在解决销量预测等实际问题中使用的越来序算法在解决销量预测等实际问题中使用的越
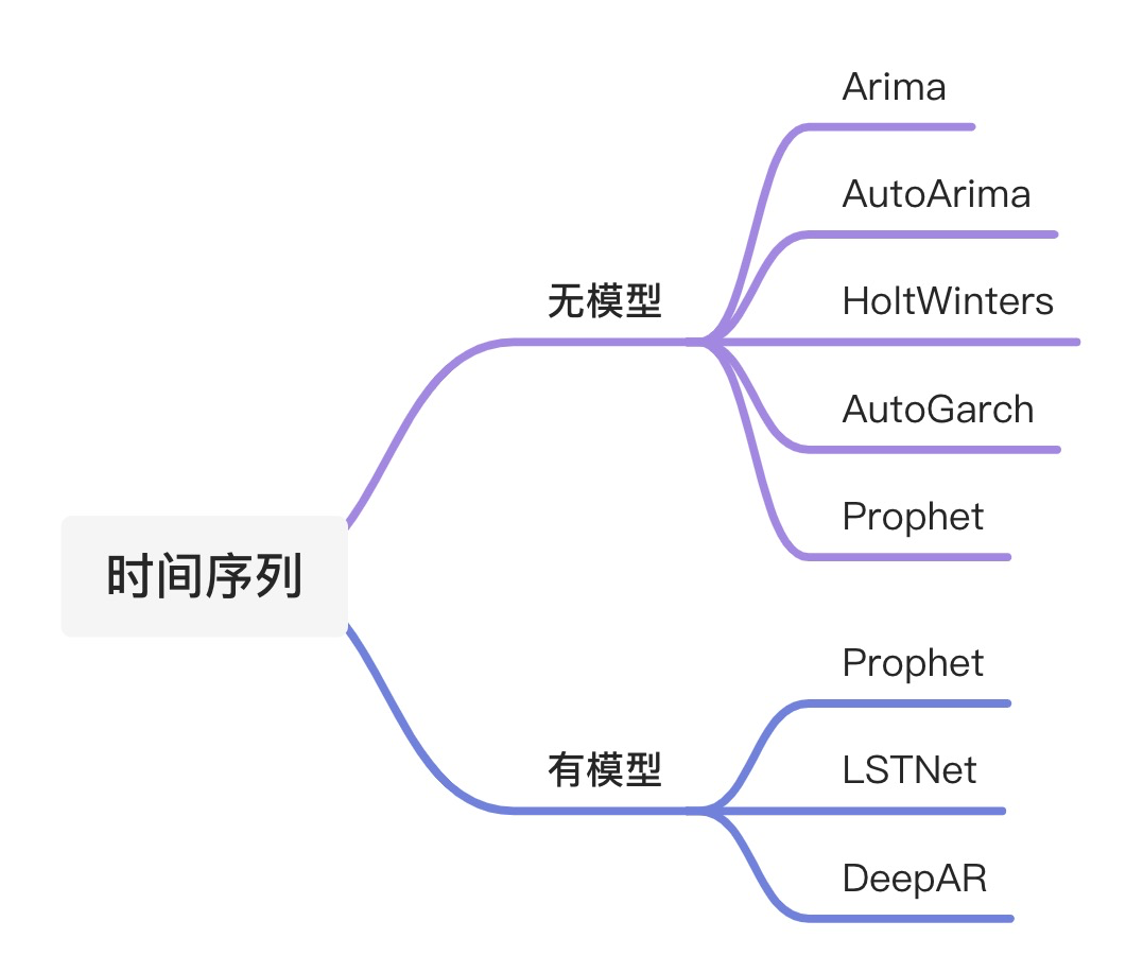
批
- 第一步,时间序列方法需要指定TimeStamp类型的时间列。如果数据中没有,有两种方式构造,
- 如果数据中有字符串类型的时间列,使用TO_TIMESTAMP('2021-12-03 00:00:00'),将数据转成TimeStamp类型。
# ts_string是String类型,数据形式是'2021-12-03 00:00:00'
sourceOp.select('TO_TIMESTAMP(ts_string) as ts, id, val')
- 如果数据没有时间列,使用CURRENT_TIMESTAMP, 以数据进入任务时间作为时间列。
sourceOp.select('CURRENT_TIMESTAMP as ts, id, val')- 第二步,将每组数据(时间列和数据列) 聚合成MTable.
GroupByBatchOp()
.setGroupByPredicate("id")
.setSelectClause("id, mtable_agg(ts, val) as data")
- 第三步,使用时间序列方法进行预测,预测结果也是MTable。
无模型,以Arima为例,
ArimaBatchOp()
.setValueCol("data")
.setOrder([1, 2, 1])
.setPredictNum(12)
.setPredictionCol("predict")有模型,以DeepAr为例,需要先训练模型,再用模型进行预测
deepARTrainBatchOp = DeepARTrainBatchOp()\
.setTimeCol("ts")\
.setSelectedCol("series")\
.setNumEpochs(10)\
.setWindow(2)\
.setStride(1)\
.linkFrom(batch_source)
deepARPredictBatchOp = DeepARPredictBatchOp(deepARTrainBatchOp)\
.setPredictNum(2)\
.setValueCol("data")\
.setPredictionCol("pred")- 第四步,使用FlattenMTableBatchOp,将MTable直接打开转换成列,
FlattenMTableBatchOp()
.setReservedCols(["id", "predict"])
.setSelectedCol("predict")
.setSchemaStr("ts timestamp, val double")或者使用查询, 将ts列时间对应的结果查询出来
LookupValueInTimeSeriesBatchOp()
.setTimeCol("ts")
.setTimeSeriesCol("predict")
.setOutputCol("out")
.setReservedCols(["id","ts"])流
- 第一步,时间序列方法需要指定TimeStamp类型的时间列。如果数据中没有,有两种方式构造,
- 如果数据中有字符串类型的时间列,使用TO_TIMESTAMP('2021-12-03 00:00:00'),将数据转成TimeStamp类型。
# ts_string是String类型,数据形式是'2021-12-03 00:00:00'
sourceOp.select('TO_TIMESTAMP(ts_string) as ts, id, val')
- 如果数据没有时间列,使用CURRENT_TIMESTAMP, 以数据进入任务时间作为时间列。
sourceOp.select('CURRENT_TIMESTAMP as ts, id, val')
- 第二步,使用窗口函数的mtable_agg_preceding(不包含当前行)或者mtable_agg(包含当前行),将窗口内的函数聚合成MTable, 以OverCount窗口为例,
over = OverCountWindowStreamOp()\
.setTimeCol("ts")\
.setPrecedingRows(4)\
.setClause("mtable_agg_preceding(ts,val) as mtable_data")Agg参考文档 http://alinklab.cn/tutorial/appendix_aggregate_function.html
窗口参考文档 https://www.yuque.com/pinshu/alink_guide/dffffm
- 第三步,使用时间序列方法,输出MTable(一列预测时间,一列预测数据) 。
无模型以Prophet为例,
tsOp = ProphetStreamOp()\
.setValueCol("mtable_data")\
.setPredictNum(1)\
.setPredictionCol("pred")\
.setPredictionDetailCol("pred_detail")
有模型,以DeepAr为例,需要先训练模型,再用模型进行预测
deepARTrainBatchOp = DeepARTrainBatchOp()\
.setTimeCol("ts")\
.setSelectedCol("series")\
.setNumEpochs(10)\
.setWindow(2)\
.setStride(1)\
.linkFrom(batch_source)
deepARPredictStreamOp = DeepARPredictBatchOp(deepARTrainStreamOp)\
.setPredictNum(2)\
.setValueCol("data")\
.setPredictionCol("pred")
- 第四步, 时间序列方法输出的结果是两列的MTable(一列时间,一列数据),如果想拆分成两列,有两种方式,
- 可以使用MTable展开组件,将MTable直接展开
flatten = FlattenMTableStreamOp()\
.setReservedCols(["id"])\
.setSelectedCol("mt")\
.setSchemaStr('ts TIMESTAMP, val double')- 使用时间序列查找组件,指定时间列进行查找
LookupVectorInTimeSeriesStreamOp()\
.setTimeCol("ts")
.setTimeSeriesCol("predict")
.setOutputCol("out")评估
使用EvalTimeSeriesBatchOp进行评估,支持的评估指标如下,其中yi是真实值,fi是预测值,y_hat是真实值均值,N是数据条数。
指标 | 名称 | 解释 | |
MSE | 均方误差 | Mean Squared Error | MSE = SSE/N |
MAE | 平均绝对误差 | Mean Absolute Error | MAE = SAE/N |
RMSE | 均方根误差 | Root Mean Squared Error | RMSE = sqrt(MSE) |
SSE | 残差平方和 | Sum of Squares for Error | SSE = sum(yi-fi)^2 |
SST | 离差平方和 | Sum of Squared for Total | SST = sum(yi-y_hat)^2 |
SSR | 回归平方和 | Sum of Squares for Regression | SSR = sum(fi_y_hat)^2 |
MAPE | 平均绝对百分误差 | Mean Absolute Percentage Error | MAPE = sum|(fi-yi)/yi|*100/N |
SMAPE | 对称平均绝对百分误差 | Symmetric Mean Absolute Percentage Error | SMAPE = sum( |(fi-yi)|/(|yi|+|fi|) )*200/N |
ND | 标准方差 | Normalized Deviation | ND = SAE / sum(|yi|) |
�
使用文档
- Arima
- AutoArima
- AutoGarch
- HoltWinter
- Prophet
- 批 https://www.yuque.com/pinshu/alink_doc/prophetbatchop
- 流 https://www.yuque.com/pinshu/alink_doc/prophetstreamop
- 批训练 https://www.yuque.com/pinshu/alink_doc/prophettrainbatchop
- 批预测 https://www.yuque.com/pinshu/alink_doc/prophetpredictbatchop
- 流预测https://www.yuque.com/pinshu/alink_doc/prophetpredictstreamop
- DeepAr
- LstNet
- 时间序列评估组件
- 时间序列查找组件