PAI-Designer上运行PyAlink组件
1. 组件介绍
PyAlink 组件是 PAI-Designer 平台上的一个算法组件,该组件能够让用户通过编写PyAlink脚本的方式调用Alink算法,并且可以与其他 Designer 的算法组件无缝衔接,共同帮助客户完成业务链路的搭建及效果验证。有了这个组件,用户可以非常容易在PAI产品端调用Alink的所有算法。比如,通过该组件调用Alink的分类算法做分类,调用Alink的回归算法做回归,调用Alink的推荐算法做推荐,或者调用多种算法去解决一个更加复杂的业务问题。
2. 组件使用方式
下面将介绍如何在 PAI-Designer 产品中通过 PyAlink 组件将一个用 PyAlink 脚本实现的业务流程在产品中使用阿里云资源运行该业务流程。这里通过对notebook中的demo(用ItemCf模型对movielens数据集进行打分)使用PyAlink组件完成其在阿里云上运行来展开介绍。首先给出的是notebook中的demo脚本:
from pyalink.alink import *
useLocalEnv(2)
PATH = "http://alink-test.oss-cn-beijing.aliyuncs.com/yuhe/movielens/"
RATING_FILE = "ratings.csv"
PREDICT_FILE = "predict.csv"
RATING_SCHEMA_STRING = "user_id long, item_id long, rating int, ts long"
ratingsData = CsvSourceBatchOp() \
.setFilePath(PATH + RATING_FILE) \
.setFieldDelimiter("\t") \
.setSchemaStr(RATING_SCHEMA_STRING)
predictData = CsvSourceBatchOp() \
.setFilePath(PATH + PREDICT_FILE) \
.setFieldDelimiter("\t") \
.setSchemaStr(RATING_SCHEMA_STRING)
itemCFModel = ItemCfTrainBatchOp() \
.setUserCol("user_id").setItemCol("item_id") \
.setRateCol("rating").linkFrom(ratingsData)
itemCF = ItemCfRateRecommender() \
.setModelData(itemCFModel) \
.setItemCol("item_id") \
.setUserCol("user_id") \
.setReservedCols(["user_id", "item_id"]) \
.setRecommCol("prediction_score")
itemCF.transform(predictData).print()下面分四步操作完成脚本在PAI-Designer 上运行。
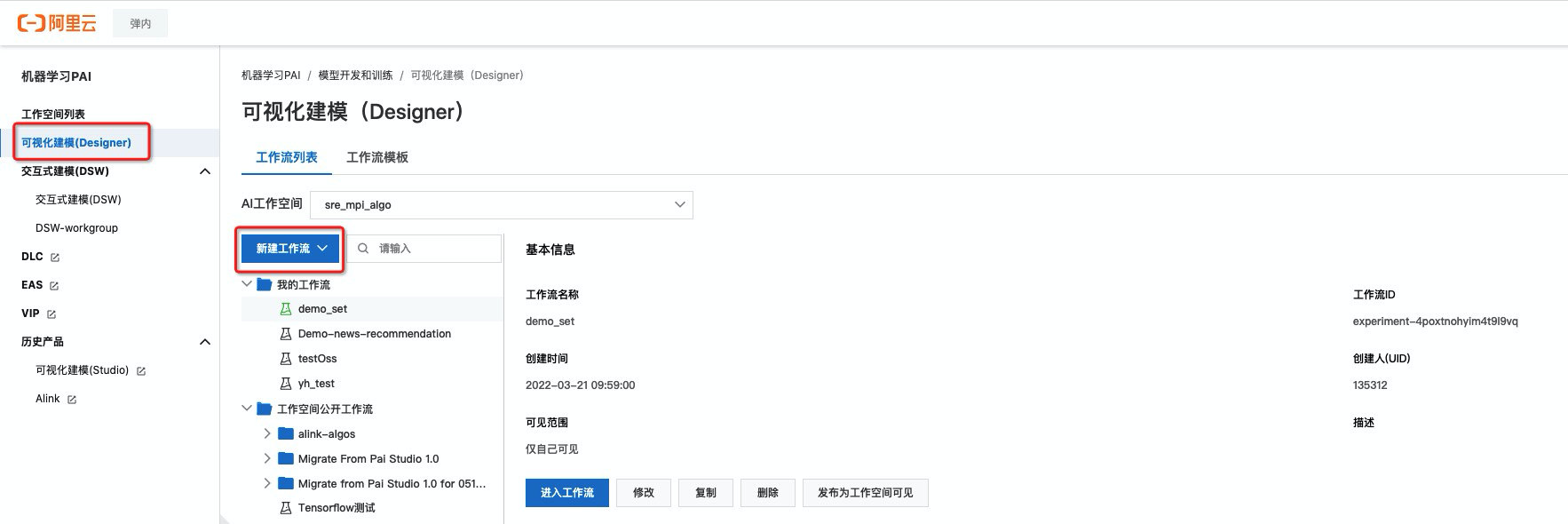
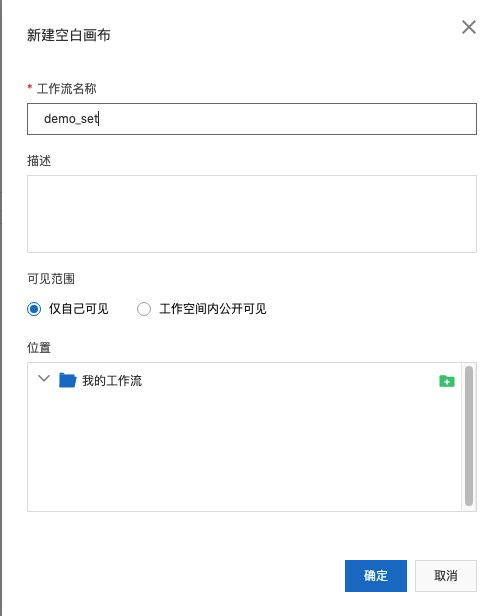
Step1. 打开PAI-Designer,并创建工作流
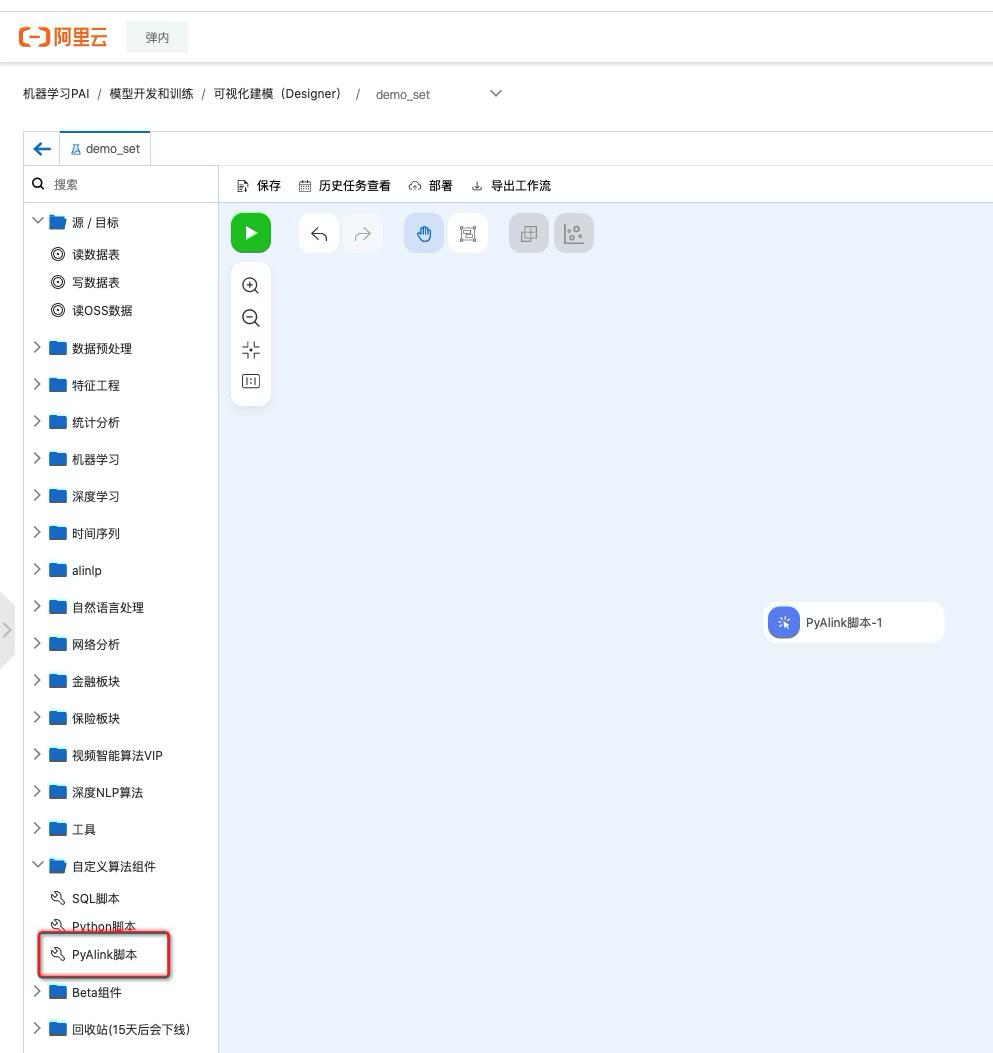
Step2. 进入新创建的工作流,拉取PyAlink组件
Step3. 将notebook的 PyAlink 脚本改写并填到代码对话框中
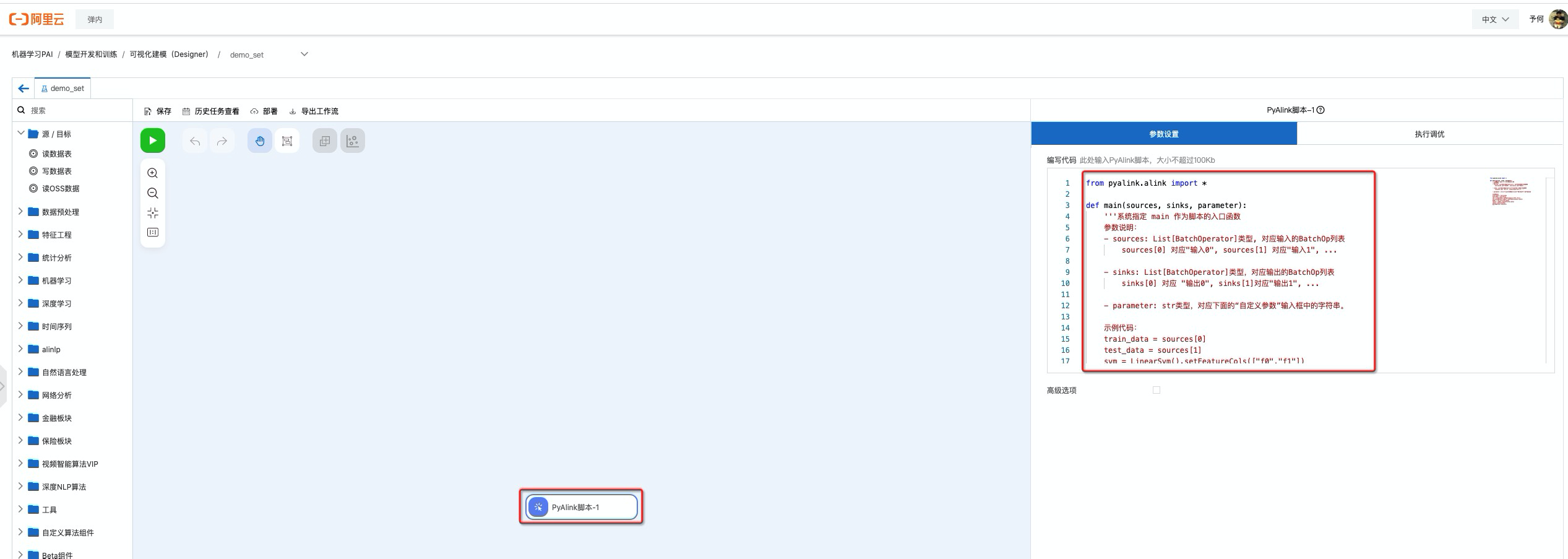 填写脚本内容如下:
填写脚本内容如下:
from pyalink.alink import *
def main(sources, sinks, parameter):
PATH = "http://alink-test.oss-cn-beijing.aliyuncs.com/yuhe/movielens/"
RATING_FILE = "ratings.csv"
PREDICT_FILE = "predict.csv"
RATING_SCHEMA_STRING = "user_id long, item_id long, rating int, ts long"
ratingsData = CsvSourceBatchOp() \
.setFilePath(PATH + RATING_FILE) \
.setFieldDelimiter("\t") \
.setSchemaStr(RATING_SCHEMA_STRING)
predictData = CsvSourceBatchOp() \
.setFilePath(PATH + PREDICT_FILE) \
.setFieldDelimiter("\t") \
.setSchemaStr(RATING_SCHEMA_STRING)
itemCFModel = ItemCfTrainBatchOp() \
.setUserCol("user_id").setItemCol("item_id") \
.setRateCol("rating").linkFrom(ratingsData);
itemCF = ItemCfRateRecommender() \
.setModelData(itemCFModel) \
.setItemCol("item_id") \
.setUserCol("user_id") \
.setReservedCols(["user_id", "item_id"]) \
.setRecommCol("prediction_score")
result = itemCF.transform(predictData)
result.link(sinks[0])
BatchOperator.execute()和notebook脚本的差别非常小,只是在数据source和sink的时候有细微差别。其中代码主体部分的修改只有一行,就是 result.link(sinks[0]) 这一行,该行将数据写出并在输出桩可以访问。由于这个demo中的数据是读取http文件,这个操作在PAI-Designer中和notebook是相同的,无需修改。
如果输入数是一个ODPS表则需要修改。此时可以直接通过输入桩读取ODPS表的数据,代码中sources[0]表示第一个输入桩对应的表,sources[1]表示第二个输入桩对应的表,依次类推,最多支持4个输入的ODPS表。具体示例代码如下:
train_data = sources[0] test_data = sources[1]
输出和输入类似,但是是将数据写出到对应的输出桩。最多支持4个输出结果表。具体代码如下:
result0.link(sinks[0]) result1.link(sinks[1])
Step4. 执行组件并察看结果
在执行组件之前需要设置资源,目前支持DLC单机多并发和MaxCompute两种模式,如果数据量比较小且是在调试验证阶段,建议使用DLC单机多并发模式,如果是数据规模很大或者是实际生产任务,则建议使用MaxCompute模式。
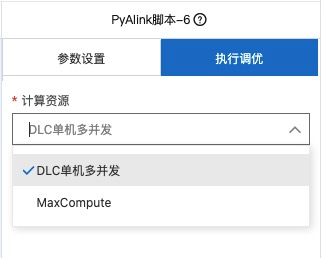
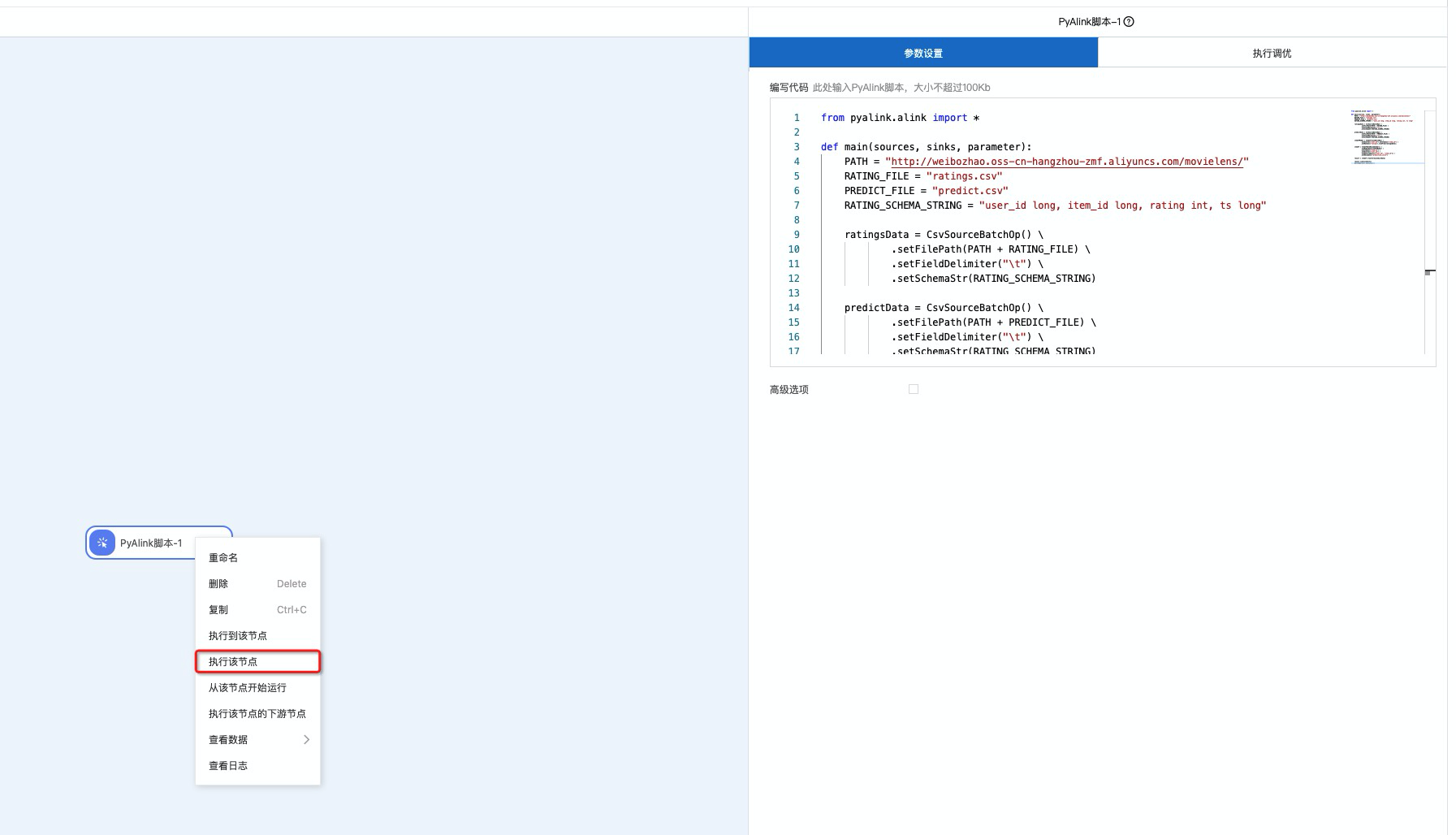
鼠标选中组件并右键选择执行该节点,就可以执行该PyAlink任务。
执行完后,可以右键选择查看数据。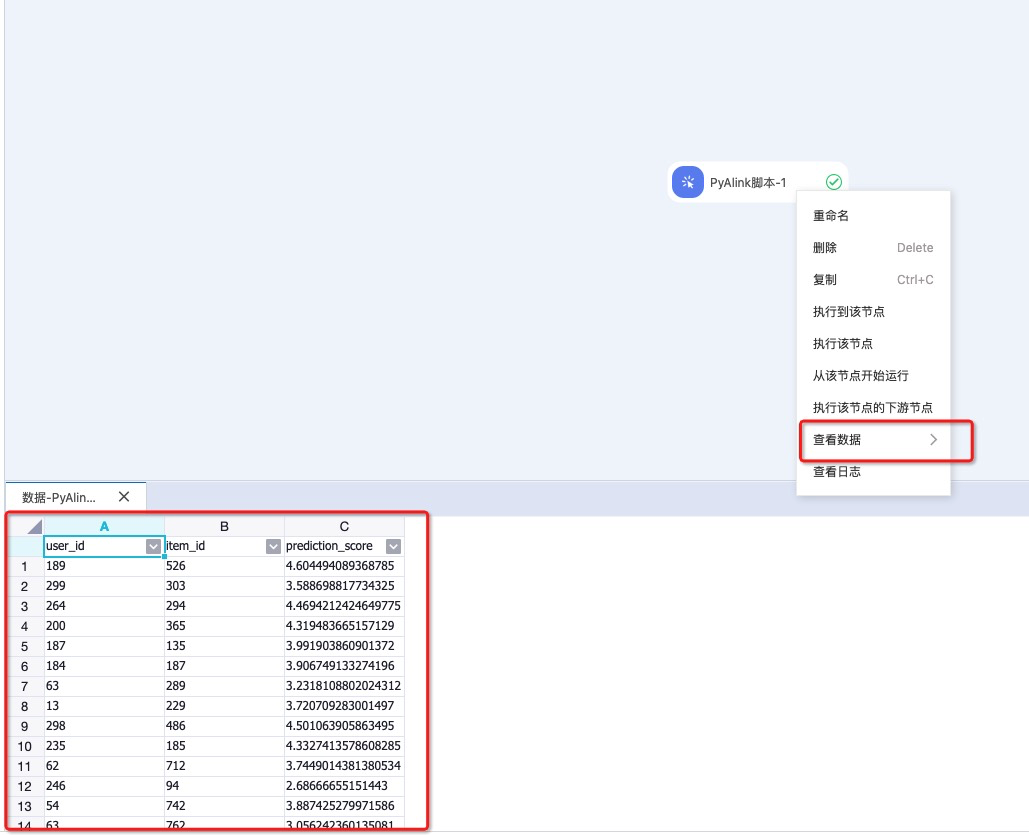
3. 数据读入写出介绍
读入数据方式
- 读取ODPS表,通过输入桩的方式从上游传入,代码示例:
train_data = sources[0] test_data = sources[1]
- 读取网络文件系统的数据,通过Alink的Source组件(CsvSourceBatchOp,AkSourceBatchOP)在代码中实现数据的读入
- 读入http格式的网络共享文件,代码示例:
ratingsData = CsvSourceBatchOp() \
.setFilePath(PATH + RATING_FILE) \
.setFieldDelimiter("\t") \
.setSchemaStr(RATING_SCHEMA_STRING)- 读入OSS网络文件,该方式需要设置数据读取路径,设置方式是在控制台,选取对应OSS路径,设置完后,代码示例如下:
model_data = AkSourceBatchOp().setFilePath("oss://xxxxxxxx/model_20220323.ak")写出数据方式
- 写出ODPS表,通过输出桩的方式写出到下游,代码示例:
result0.link(sinks[0]) result1.link(sinks[1]) BatchOperator.execute()
- 写出OSS网络文件,该方式需要设置数据写出路径,设置方式是在控制台,选取对应OSS路径,设置完后,代码示例如下:
result.link(AkSinkBatchOp() \
.setFilePath("oss://xxxxxxxx/model_20220323.ak") \
.setOverwriteSink(True))
BatchOperator.execute()其中 xxxxxxxx 是bucket名字 + 模型路径。
4. 与其他Designer组件组合使用
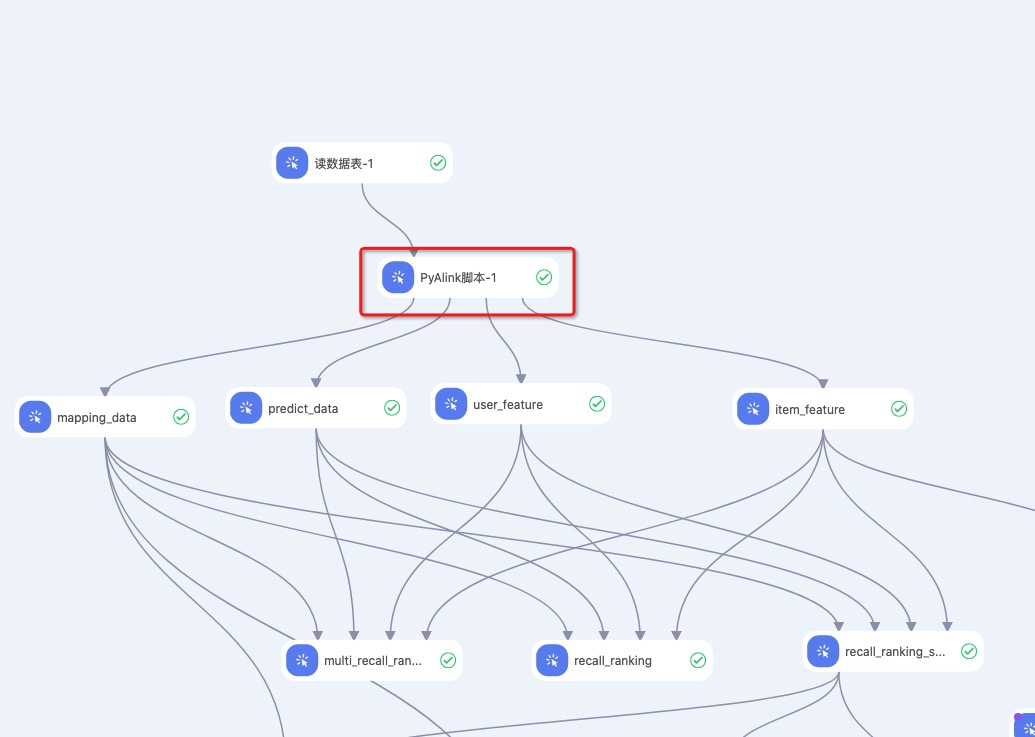
上图给出的是PyAlink脚本与其他的算法组件组合使用的例子,这个例子展示了PyAlink的输入输出桩和其他组件无任何差别,可以相互连接共同使用。
5. PyAlink 组件训练生成的模型如何部署到EAS
1. 生成待部署的模型
目前PyAlink生成PipelineModel可以部署到EAS,下面给出一个生成PipelineModel的脚本示例:
from pyalink.alink import *
def main(sources, sinks, parameter):
PATH = "http://alink-test.oss-cn-beijing.aliyuncs.com/yuhe/movielens/"
RATING_FILE = "ratings.csv"
PREDICT_FILE = "predict.csv"
RATING_SCHEMA_STRING = "user_id long, item_id long, rating int, ts long"
ratingsData = CsvSourceBatchOp() \
.setFilePath(PATH + RATING_FILE) \
.setFieldDelimiter("\t") \
.setSchemaStr(RATING_SCHEMA_STRING)
predictData = CsvSourceBatchOp() \
.setFilePath(PATH + PREDICT_FILE) \
.setFieldDelimiter("\t") \
.setSchemaStr(RATING_SCHEMA_STRING)
itemCFModel = ItemCfTrainBatchOp() \
.setUserCol("user_id").setItemCol("item_id") \
.setRateCol("rating").linkFrom(ratingsData);
itemCF = ItemCfRateRecommender() \
.setModelData(itemCFModel) \
.setItemCol("item_id") \
.setUserCol("user_id") \
.setReservedCols(["user_id", "item_id"]) \
.setRecommCol("prediction_score")
model = PipelineModel(itemCF)
model.save().link(AkSinkBatchOp() \
.setFilePath("oss://weibozhao/model.ak") \
.setOverwriteSink(True))
BatchOperator.execute()上面的脚本会生成一个模型文件,存储在oss中,该模型文件可以够直接部署到EAS。
2. 生成EAS配置文件
配置文件可以通过下面的脚本生成。不妨假设生成的配置文件为config.json
# EAS的配置文件
import json
# 生成 EAS 模型配置
eas_config = {
"name": "recommendation_demo",
"model_path": "http://weibozhao.oss-cn-hangzhou-zmf.aliyuncs.com/model/recomm_model.ak",
"processor": "alink_1.5.8",
"metadata": {
"instance": 1,
"memory": 2048,
"region":"cn-beijing"
}
}
print(json.dumps(eas_config, indent=4))config文件中的关键字解释:
name 是该部署模型的名字,用户自己定义。
model_path 是模型的OSS路径。
model_entry 是ak模型文件的名字。
processor 是推理时调用的Jar包。
其他一些参数可以参考EAS部署文档:https://help.aliyun.com/document_detail/111031.html?spm=a2c4g.11186623.6.763.6c307773fEXVaJ
{
"metadata": {
"cpu": 2,
"gpu": 0,
"instance": 1,
"memory": 8000,
"name": "recommendation_demo"
},
"model_path": "oss://model/recomm_model.ak",
"name": "recommendation_demo",
"processor": "alink_1.5.8"
}3. 将模型部署到EAS
# 下载 eascmd: https://help.aliyun.com/document_detail/195500.html?spm=a2c4g.11186623.6.728.6d7437553LnENf
# 配置好 ak、endpoint等信息
# 将上面的输出保存到文件 config.json ,然后在命令行运行下面的命令
./eascmd64 -i {EAS AccessKeyId} -k {EAS AccessKeySecret} -e pai-eas.cn-beijing.aliyuncs.com create config.json4. PyAlink 支持一键部署 EAS 功能
- 用PyAlink训练生成待部署的Pipeline模型,并写出到最后一个桩
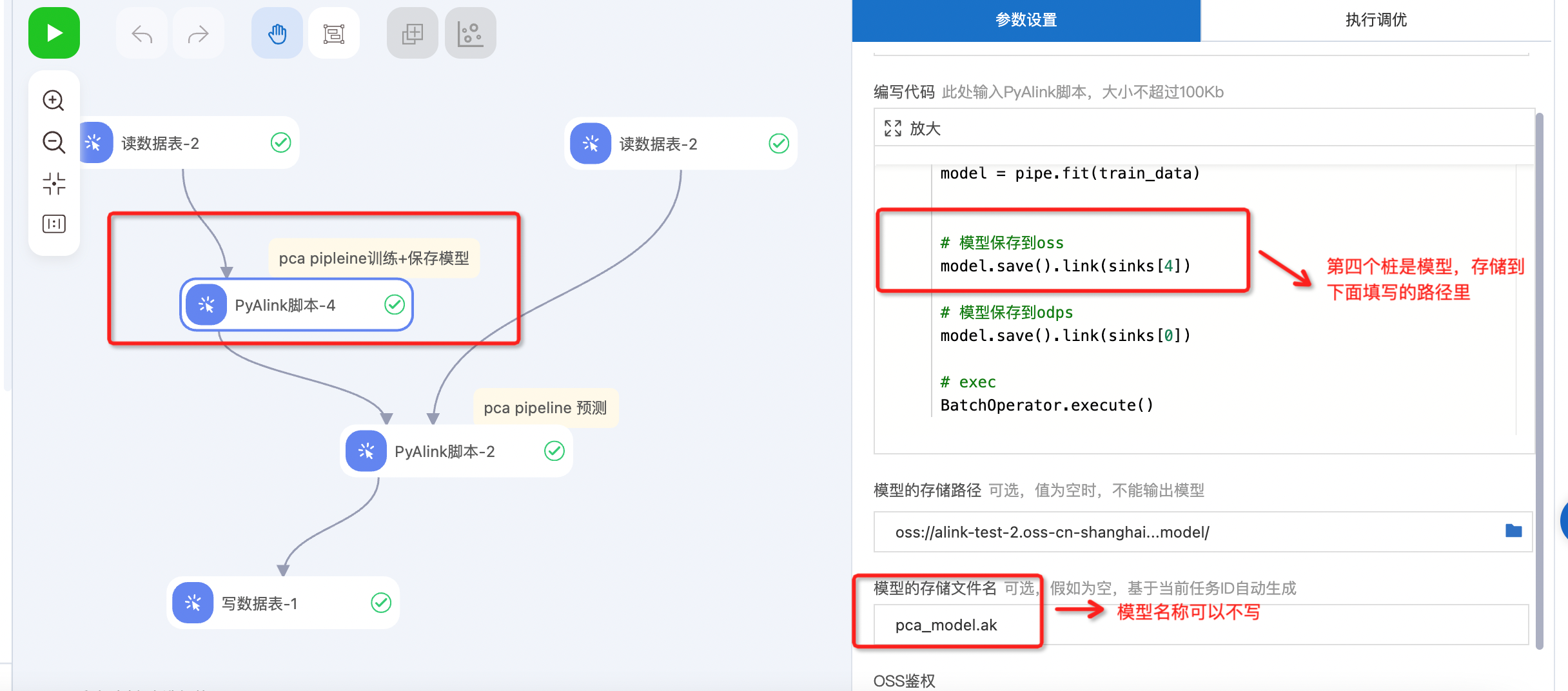
- 点击一键部署按钮
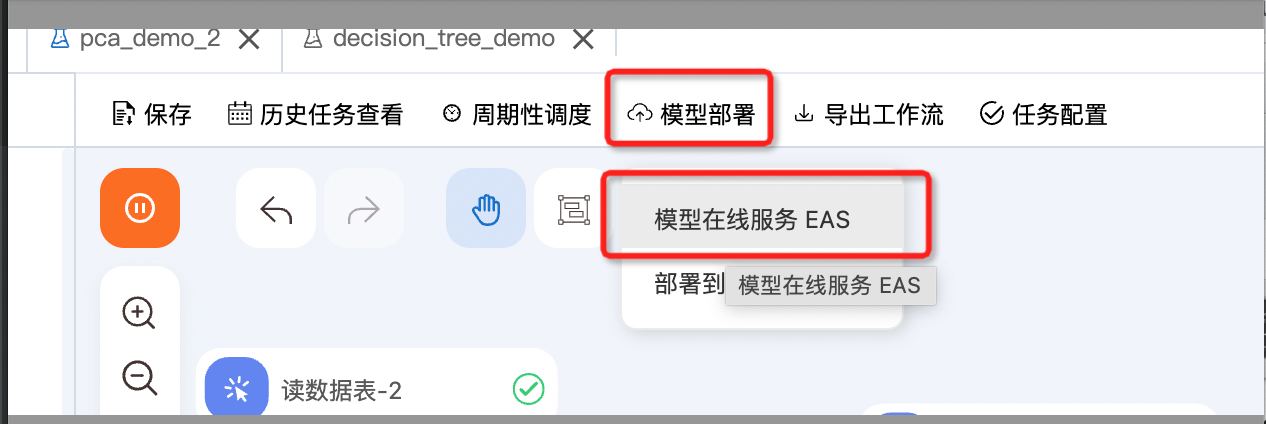
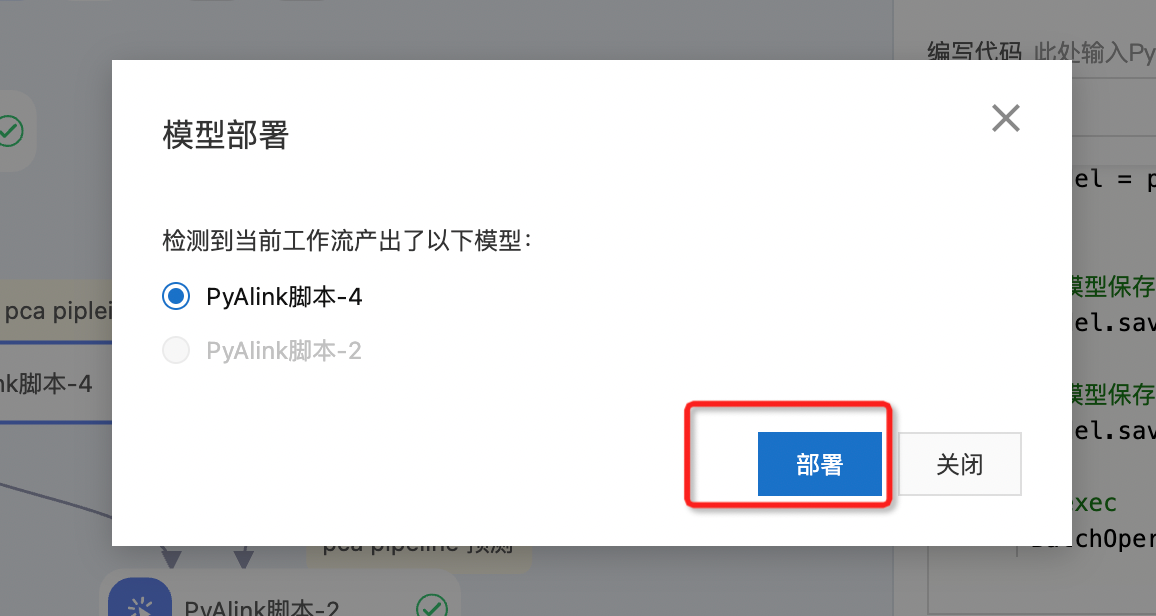
- 部署
- 填写部署服务的名字及资源配置
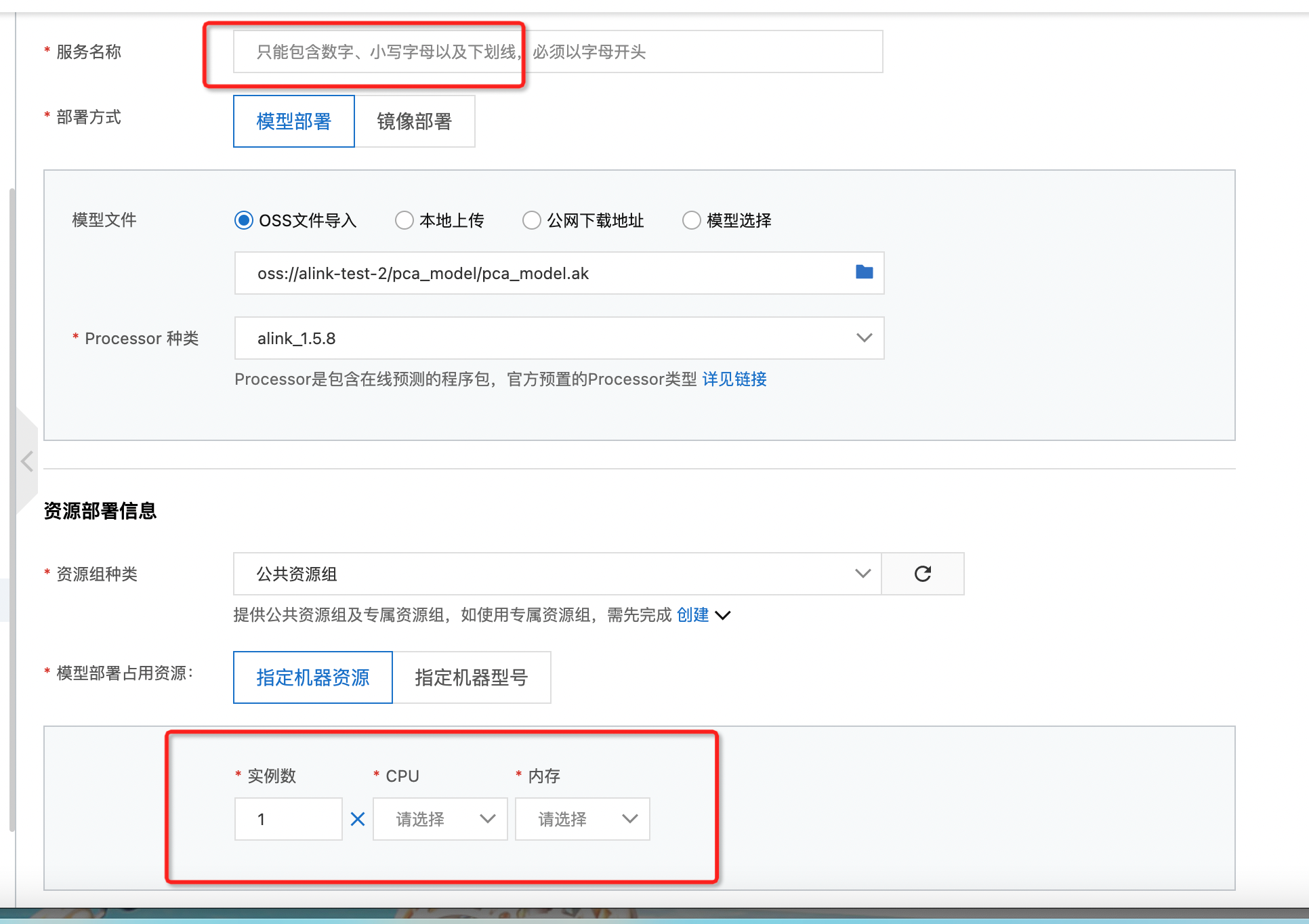
- 点击部署完成服务部署