同类别的组件
- 生存回归预测
- 生存回归训练
- Bert文本对回归预测
- Bert文本对回归训练
- Bert文本回归预测
- Bert文本回归训练
- CART决策树回归预测
- CART决策树回归训练
- 决策树回归预测
- 决策树回归训练
- FM回归预测
- FM回归训练
- GBDT回归预测
- GBDT回归训练
- 广义线性回归评估
- 广义线性回归预测
- 广义线性回归训练
- 保序回归预测
- 保序回归训练
- KerasSequential回归预测
- KerasSequential回归训练
- Lasso回归预测
- Lasso回归训练
- 线性回归预测
- 线性回归Stepwise预测
- 线性回归Stepwise训练
- 线性回归训练
- 线性SVR预测
- 线性SVR训练
- 随机森林回归预测
- 随机森林回归训练
- 岭回归预测
- 岭回归训练
- XGBoost 回归预测
- XGBoost 回归训练
保序回归训练 (IsotonicRegTrainBatchOp)
Java 类名:com.alibaba.alink.operator.batch.regression.IsotonicRegTrainBatchOp
Python 类名:IsotonicRegTrainBatchOp
功能介绍
保序回归在观念上是寻找一组非递减的片段连续线性函数(piecewise linear continuous functions),即保序函数,使其与样本尽可能的接近。
保序回归的输入在Alink中称分别为特征(feature)、标签(label)和权重(weight),特征可以是数值或向量,如果是向量还需要设定特征索引
(feature index),组件将使用该维进行计算。保序回归的目标是求解一个能使$\textstyle \sum_i{w_i(y_i-\hat{y}_i)^2}$最小的序列$\hat{y}$,
若选择保增序,该序列还应满足$X_i<X_j$时$\hat{y}_i\le\hat{y}_j$,若选择保降序满足$X_i<X_j$时$\hat{y}_i\ge\hat{y}_j$。
下图中,散点图是训练数据,折线图是得到的保序回归模型,对于训练数据中没有的特征,使用线性插值得到其标签。对应训练和预测代码见示例。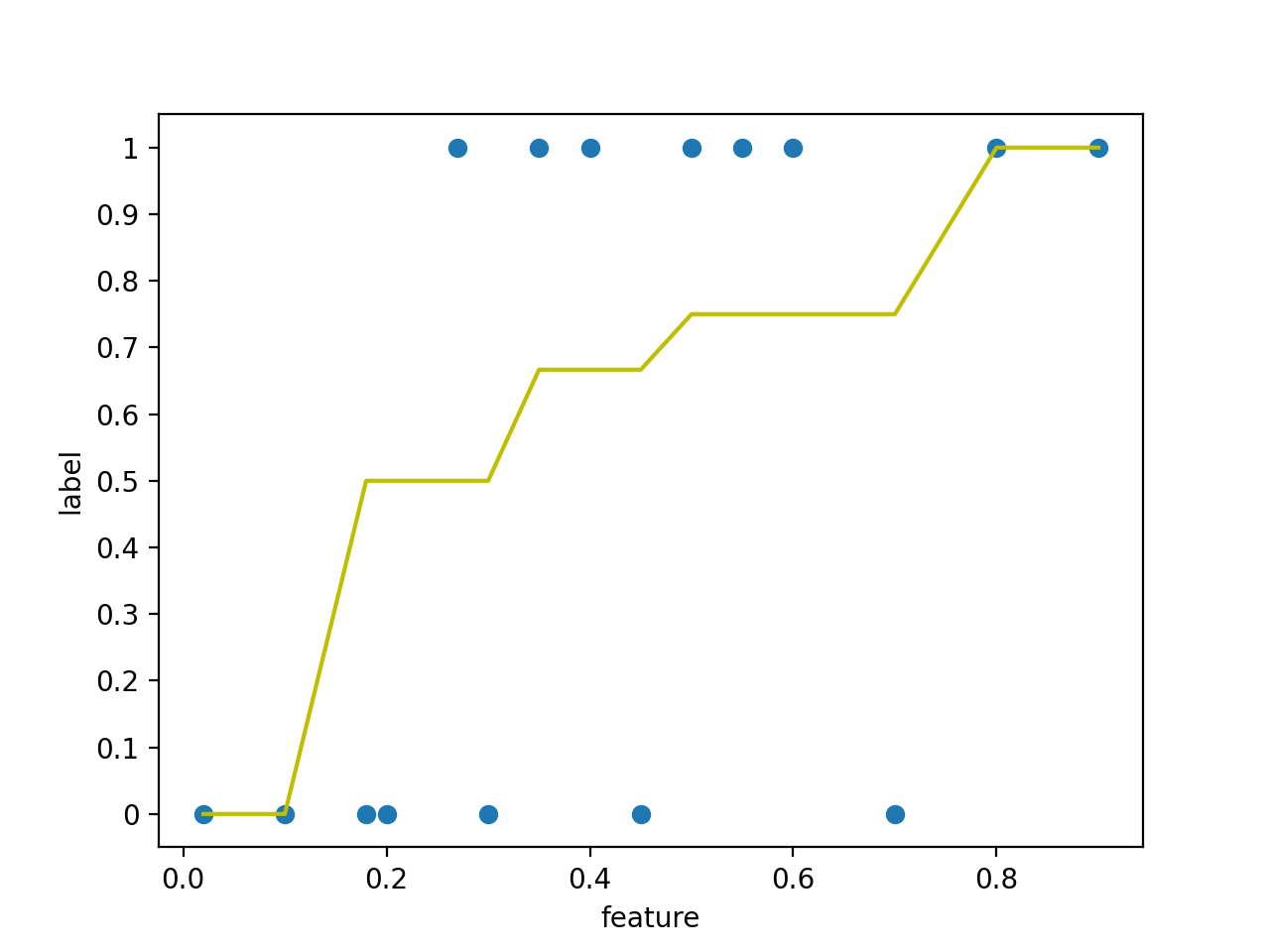
参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
|---|---|---|---|---|---|---|
| labelCol | 标签列名 | 输入表中的标签列名 | String | ✓ | 所选列类型为 [BIGDECIMAL, BIGINTEGER, BYTE, DOUBLE, FLOAT, INTEGER, LONG, SHORT] | |
| featureCol | 特征列名 | 特征列的名称 | String | 所选列类型为 [BIGDECIMAL, BIGINTEGER, BYTE, DOUBLE, FLOAT, INTEGER, LONG, SHORT] | null | |
| featureIndex | 训练特征所在维度 | 训练特征在输入向量的维度索引 | Integer | x >= 0 | 0 | |
| isotonic | 输出序列是否 | 输出序列是否递增 | Boolean | true | ||
| vectorCol | 向量列名 | 向量列对应的列名,默认值是null | String | 所选列类型为 [DENSE_VECTOR, SPARSE_VECTOR, STRING, VECTOR] | null | |
| weightCol | 权重列名 | 权重列对应的列名 | String | 所选列类型为 [BIGDECIMAL, BIGINTEGER, BYTE, DOUBLE, FLOAT, INTEGER, LONG, SHORT] | null |
代码示例
Python 代码
from pyalink.alink import *
import pandas as pd
useLocalEnv(1)
df = pd.DataFrame([
[0.35, 1],
[0.6, 1],
[0.55, 1],
[0.5, 1],
[0.18, 0],
[0.1, 1],
[0.8, 1],
[0.45, 0],
[0.4, 1],
[0.7, 0],
[0.02, 1],
[0.3, 0],
[0.27, 1],
[0.2, 0],
[0.9, 1]
])
data = BatchOperator.fromDataframe(df, schemaStr="feature double, label double")
trainOp = IsotonicRegTrainBatchOp()\
.setFeatureCol("feature")\
.setLabelCol("label")
model = trainOp.linkFrom(data)
predictOp = IsotonicRegPredictBatchOp()\
.setPredictionCol("result")
predictOp.linkFrom(model, data).print()
Java 代码
import org.apache.flink.types.Row;
import com.alibaba.alink.operator.batch.BatchOperator;
import com.alibaba.alink.operator.batch.regression.IsotonicRegPredictBatchOp;
import com.alibaba.alink.operator.batch.regression.IsotonicRegTrainBatchOp;
import com.alibaba.alink.operator.batch.source.MemSourceBatchOp;
import org.junit.Test;
import java.util.Arrays;
import java.util.List;
public class IsotonicRegTrainBatchOpTest {
@Test
public void testIsotonicRegTrainBatchOp() throws Exception {
List <Row> df = Arrays.asList(
Row.of(0.35, 1.0),
Row.of(0.6, 1.0),
Row.of(0.55, 1.0),
Row.of(0.5, 1.0),
Row.of(0.18, 0.0),
Row.of(0.1, 1.0),
Row.of(0.8, 1.0),
Row.of(0.45, 0.0),
Row.of(0.4, 1.0),
Row.of(0.7, 0.0),
Row.of(0.02, 1.0),
Row.of(0.3, 0.0),
Row.of(0.27, 1.0),
Row.of(0.2, 0.0),
Row.of(0.9, 1.0)
);
BatchOperator <?> data = new MemSourceBatchOp(df, "feature double, label double");
BatchOperator <?> trainOp = new IsotonicRegTrainBatchOp()
.setFeatureCol("feature")
.setLabelCol("label");
BatchOperator model = trainOp.linkFrom(data);
BatchOperator <?> predictOp = new IsotonicRegPredictBatchOp()
.setPredictionCol("result");
predictOp.linkFrom(model, data).print();
}
}
运行结果
模型结果
| model_id | model_info |
|---|---|
| 0 | {“vectorCol”:“"col2"”,“featureIndex”:“0”,“featureCol”:null} |
| 1048576 | [0.02,0.3,0.35,0.45,0.5,0.7] |
| 2097152 | [0.5,0.5,0.6666666865348816,0.6666666865348816,0.75,0.75] |
预测结果
| col1 | col2 | col3 | pred |
|---|---|---|---|
| 1.0 | 0.9 | 1.0 | 0.75 |
| 0.0 | 0.7 | 1.0 | 0.75 |
| 1.0 | 0.35 | 1.0 | 0.6666666865348816 |
| 1.0 | 0.02 | 1.0 | 0.5 |
| 1.0 | 0.27 | 1.0 | 0.5 |
| 1.0 | 0.5 | 1.0 | 0.75 |
| 0.0 | 0.18 | 1.0 | 0.5 |
| 0.0 | 0.45 | 1.0 | 0.6666666865348816 |
| 1.0 | 0.8 | 1.0 | 0.75 |
| 1.0 | 0.6 | 1.0 | 0.75 |
| 1.0 | 0.4 | 1.0 | 0.6666666865348816 |
| 0.0 | 0.3 | 1.0 | 0.5 |
| 1.0 | 0.55 | 1.0 | 0.75 |
| 0.0 | 0.2 | 1.0 | 0.5 |
| 1.0 | 0.1 | 1.0 | 0.5 |