- Alink权威指南:机器学习实例入门(Python版)
- Alink教程(Python版)目录
- Alink教程(Python版)代码的运行攻略
- Alink教程(Python版)的数据和资料链接
- 第1章 Alink快速上手
- 第1.1节 Alink是什么
- 第1.2节 免费下载、安装
- 第1.2.1节 PyAlink快速开始
- 第1.2.1.1节 PyAlink安装准备——MacOS
- 第1.2.1.2节 PyAlink安装准备——阿里云服务器
- 第1.2.1.3节 如何安装最新版本PyAlink?
- 第1.2.1.4节 PyAlink的版本查询、卸载旧版本
- 第1.2.2节 在 Flink 集群上运行 PyAlink 任务
- 第1.3节 Alink的功能
- 第1.4节 关于数据和代码
- 第1.5节 简单示例
- 第2章 系统概况与核心概念
- 第2.1节 基本概念
- 第2.2节 批式任务与流式任务
- 第2.3节 Alink=A+link
- 第2.4节 Pipeline与PipelineModel
- 第2.5节 触发Alink任务的执行
- 第2.5.1节 批式任务打印输出中间结果
- 第2.6节 模型信息显示
- 第2.7节 文件系统与数据库
- 第2.8节 Schema String
- 第3章 文件系统与数据文件
- 第3.2.4节 读取Parquet文件格式数据
- 第3.2.5节 定时输出流式数据
- 第3.2.6节 读取分区格式数据
- 第4章 数据库与数据表
- 第4.5节 Alink连接Kafka数据源
- 第5章 支持Flink SQL
- 第5.3.4节 Flink与Alink的数据转换
- 第6章 用户定义函数(UDF/UDTF)
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第10章 特征的转化
- 第11章 构造新特征
- 第12章 从二分类到多分类
- 第13章 常用的多分类算法
- 第14章 在线学习
- 第15章 回归的由来
- 第16章 常用的回归算法
- 第17章 常用的聚类算法
- 第18章 批式与流式聚类
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第22章 单词向量化
- 第23章 情感分析
- 第23.5节 中文情感分析示例
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 第25.1节 深度学习组件简介
- 第25.1.1节 深度学习功能概览
- 第25.1.2节 KerasSequential组件
- 第25.1.3节 深度学习相关插件的下载
- 第25.2节 手写识别MNIST
- 第25.3节 深度回归算法
- 第25.4节 运行TensorFlow模型
- 第25.5节 运行PyTorch模型
- 第25.6节 使用自定义 TensorFlow 脚本
- 第25.7节 运行ONNX模型
- 第26章 图像识别
- 第26.1节 数据准备
- 第26.2节 构造二分类模型
- 第26.3节 使用TF Hub模型
- 第1章 Alink快速上手
- 在Flink集群部署Alink
- 在易用性方面的小技巧
- 流式组件输出数据的显示(基于Jupyter环境)
- Alink插件下载器
- 第2章 系统概况与核心概念
- Failed to load BLAS警告——Mac OS上解决方法
- 在Linux,Mac下定时执行Alink任务
- Failed to load BLAS警告——Linux上解决方法
- 第3章 文件系统与数据文件
- 第4章 数据库与数据表
- Catalog中设置数据库分区【Alink使用技巧】
- 在MacOS上搭建Kafka
- 在Windows上搭建Kafka
- 第5章 支持Flink SQL
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第11章 构造新特征
- GBDT+LR 一体化模型训练与预测
- GBDT+FM 一体化模型训练及预测
- 第13章 常用的多分类算法
- 第14章 在线学习 Ftrl Demo
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 基于图算法实现金融风控
- 如何使用Alink时间序列算法?
- 如何使用Alink窗口特征生成?
第2.1节 基本概念
数据集(DataSet)与数据流(DataStream)的区别在于用户是否可以假定数据有界。数据集(DataSet)的数据有界就意味着,数据是静止的、确定的,内容和个数都不会变化。
在逐条读取数据时,数据集(DataSet)的数据是有界的、个数确定,我们可以执行某些操作。比如,统计该数据集的记录总数,计算平均值、方差等统计量;在逻辑上,可以看作把该数据集按照某个操作处理完,得到一个新的数据集,然后对该新数据集进行另外一个操作,得到另一个新的数据集。
批式(Batch)数据对应着数据集(DataSet),流式(Stream)数据对应着数据流(DataStream)。
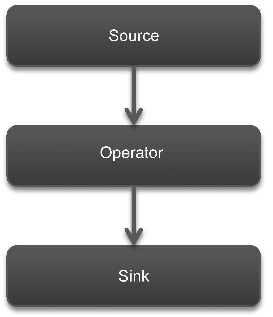
数据处理的基本流程就是三部分:数据源(Source)、算法组件(Operator)和数据导出(Sink),如下图所示。
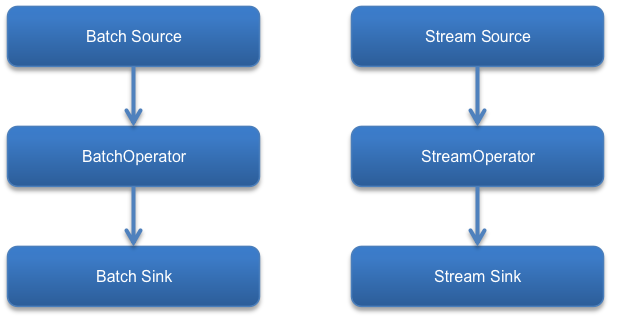
考虑到数据集和数据流之间的区别,处理操作被分为批式处理(Batch Processing)和流式处理(Stream Processing),如下图所示。在批式处理中,批式数据源组件(Batch Source)读入的数据为数据集;批式导出组件(Batch Sink)将数据集导出到文件系统或数据库;批式算法组件(BatchOperator)的输入和计算结果都为数据集。对于流式处理,流式数据源组件(Stream Source)用来接入数据流;流式导出组件(Stream Sink)负责将数据流导出,即将数据流导出到文件系统或数据库;流式算法组件(StreamOperator)的处理粒度是单条数据,即从输入的数据流中逐条获取数据进行计算,该计算结果为若干条数据,这些数据会进入输出数据流。连接流式数据源组件、各个流式算法组件和流式导出组件,构成数据流的管道。
Alink将Flink Table作为数据集和数据流的统一表示,其中数据行的类型为org.apache.flink. types.Row。
Alink为了统一各算法模块间交换数据的格式,确定将Row格式作为各算法处理的单条数据的标准类型;相应的批数据与流数据的类型为Flink Table。如此一来,SQL操作与算法模块间可以通过Flink Table来传递数据,这样SQL操作与算法操作就可以出现在同一个工作流中,方便用户使用。