- Alink权威指南:机器学习实例入门(Python版)
- Alink教程(Python版)目录
- Alink教程(Python版)代码的运行攻略
- Alink教程(Python版)的数据和资料链接
- 第1章 Alink快速上手
- 第1.1节 Alink是什么
- 第1.2节 免费下载、安装
- 第1.2.1节 PyAlink快速开始
- 第1.2.1.1节 PyAlink安装准备——MacOS
- 第1.2.1.2节 PyAlink安装准备——阿里云服务器
- 第1.2.1.3节 如何安装最新版本PyAlink?
- 第1.2.1.4节 PyAlink的版本查询、卸载旧版本
- 第1.2.2节 在 Flink 集群上运行 PyAlink 任务
- 第1.3节 Alink的功能
- 第1.4节 关于数据和代码
- 第1.5节 简单示例
- 第2章 系统概况与核心概念
- 第2.1节 基本概念
- 第2.2节 批式任务与流式任务
- 第2.3节 Alink=A+link
- 第2.4节 Pipeline与PipelineModel
- 第2.5节 触发Alink任务的执行
- 第2.5.1节 批式任务打印输出中间结果
- 第2.6节 模型信息显示
- 第2.7节 文件系统与数据库
- 第2.8节 Schema String
- 第3章 文件系统与数据文件
- 第3.2.4节 读取Parquet文件格式数据
- 第3.2.5节 定时输出流式数据
- 第3.2.6节 读取分区格式数据
- 第4章 数据库与数据表
- 第4.5节 Alink连接Kafka数据源
- 第5章 支持Flink SQL
- 第5.3.4节 Flink与Alink的数据转换
- 第6章 用户定义函数(UDF/UDTF)
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第10章 特征的转化
- 第11章 构造新特征
- 第12章 从二分类到多分类
- 第13章 常用的多分类算法
- 第14章 在线学习
- 第15章 回归的由来
- 第16章 常用的回归算法
- 第17章 常用的聚类算法
- 第18章 批式与流式聚类
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第22章 单词向量化
- 第23章 情感分析
- 第23.5节 中文情感分析示例
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 第25.1节 深度学习组件简介
- 第25.1.1节 深度学习功能概览
- 第25.1.2节 KerasSequential组件
- 第25.1.3节 深度学习相关插件的下载
- 第25.2节 手写识别MNIST
- 第25.3节 深度回归算法
- 第25.4节 运行TensorFlow模型
- 第25.5节 运行PyTorch模型
- 第25.6节 使用自定义 TensorFlow 脚本
- 第25.7节 运行ONNX模型
- 第26章 图像识别
- 第26.1节 数据准备
- 第26.2节 构造二分类模型
- 第26.3节 使用TF Hub模型
- 第1章 Alink快速上手
- 在Flink集群部署Alink
- 在易用性方面的小技巧
- 流式组件输出数据的显示(基于Jupyter环境)
- Alink插件下载器
- 第2章 系统概况与核心概念
- Failed to load BLAS警告——Mac OS上解决方法
- 在Linux,Mac下定时执行Alink任务
- Failed to load BLAS警告——Linux上解决方法
- 第3章 文件系统与数据文件
- 第4章 数据库与数据表
- Catalog中设置数据库分区【Alink使用技巧】
- 在MacOS上搭建Kafka
- 在Windows上搭建Kafka
- 第5章 支持Flink SQL
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第11章 构造新特征
- GBDT+LR 一体化模型训练与预测
- GBDT+FM 一体化模型训练及预测
- 第13章 常用的多分类算法
- 第14章 在线学习 Ftrl Demo
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 基于图算法实现金融风控
- 如何使用Alink时间序列算法?
- 如何使用Alink窗口特征生成?
第25.5节 运行PyTorch模型
在本章的第2、3节介绍了使用Alink提供的深度学习组件KerasSequentialClassifier和KerasSequentialRegressor进行分类和回归模型的训练、预测。
实际应用中,经常需要使用TensorFlow或着PyTorch训练好的模型,对流式数据、批式数据进行预测。Alink提供了相应的流式、批式和Pipeline组件适配TensorFlow或着PyTorch模型。
本节重点介绍与PyTorch模型相关的操作。
25.5.1 生成PyTorch模型
本节所需的PyTorch模型文件mnist_model_pytorch.pt,已经被放到了OSS上,本节后面的实验会直接从网络读取该模型。https://alink-release.oss-cn-beijing.aliyuncs.com/data-files/mnist_model_pytorch.pt
如果读者有兴趣,可以在PyTorch环境,运行下面代码便可生成PyTorch模型,从而被Alink相关组件使用。注意:PyTorch模型执需要打包为".pt"文件,便于Alink相关组件导入模型。建议的打包示例代码在下面代码的最后部分。
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor
train_data = datasets.MNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
train_loader = torch.utils.data.dataloader.DataLoader(dataset=train_data, batch_size=64, shuffle=True)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 32, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2))
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(32, 64, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.conv3 = torch.nn.Sequential(
torch.nn.Conv2d(64, 64, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.dense = torch.nn.Sequential(
torch.nn.Linear(64 * 3 * 3, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 10)
)
def forward(self, x):
conv1_out = self.conv1(x)
conv2_out = self.conv2(conv1_out)
conv3_out = self.conv3(conv2_out)
res = conv3_out.view(conv3_out.size(0), -1)
out = self.dense(res)
return out
model = Net()
print(model)
optimizer = torch.optim.Adam(model.parameters())
loss_func = torch.nn.CrossEntropyLoss()
for epoch in range(5):
print('epoch {}'.format(epoch + 1))
train_loss = 0.
train_acc = 0.
for batch_x, batch_y in train_loader:
batch_x, batch_y = torch.autograd.Variable(batch_x), torch.autograd.Variable(batch_y)
out = model(batch_x)
loss = loss_func(out, batch_y)
train_loss += loss.item()
pred = torch.max(out, 1)[1]
train_correct = (pred == batch_y).sum()
train_acc += train_correct.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Train Loss: {:.6f}, Acc: {:.6f}'.format(train_loss / (len(
train_data)), train_acc / (len(train_data))))
traced = torch.jit.trace(model, (torch.rand(1, 1, 28, 28)))
torch.jit.save(traced, "mnist_model_pytorch.pt")输出模型及训练信息如下:
Net(
(conv1): Sequential(
(0): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv2): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(conv3): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(dense): Sequential(
(0): Linear(in_features=576, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=10, bias=True)
)
)
epoch 1
Train Loss: 0.003327, Acc: 0.933000
epoch 2
Train Loss: 0.000876, Acc: 0.982667
epoch 3
Train Loss: 0.000592, Acc: 0.987783
epoch 4
Train Loss: 0.000466, Acc: 0.990467
epoch 5
Train Loss: 0.000403, Acc: 0.99173325.5.2 批式任务中使用PyTorch模型
使用TorchModelPredictBatchOp组件,可以加载PyTorch模型进行批式预测。关于该组件的详细说明参见Alink文档 https://www.yuque.com/pinshu/alink_doc/torchmodelpredictbatchop .
使用PyTorch模型前,还需要将输入数据列的类型转换为Tensor格式,可以使用VectorToTensorBatchOp组件。具体代码如下所示:
AkSourceBatchOp()\
.setFilePath(Chap13_DATA_DIR + Chap13_DENSE_TEST_FILE)\
.link(\
VectorToTensorBatchOp()\
.setTensorDataType("float")\
.setTensorShape([1, 1, 28, 28])\
.setSelectedCol("vec")\
.setOutputCol("tensor")\
.setReservedCols(["label"])
)\
.link(\
TorchModelPredictBatchOp()\
.setModelPath(
"https://alink-release.oss-cn-beijing.aliyuncs.com/data-files/mnist_model_pytorch.pt")\
.setSelectedCols(["tensor"])\
.setOutputSchemaStr("output_1 FLOAT_TENSOR")
)\
.lazyPrint(3)\
.link(\
UDFBatchOp()\
.setFunc(get_max_index)\
.setSelectedCols(["output_1"])\
.setOutputCol("pred")
)\
.lazyPrint(3)\
.link(\
EvalMultiClassBatchOp()\
.setLabelCol("label")\
.setPredictionCol("pred")\
.lazyPrintMetrics()
)
BatchOperator.execute()这里用到了一个自定义函数,具体定义如下:
import numpy as np
@udf(input_types=[AlinkDataTypes.TENSOR()], result_type=AlinkDataTypes.INT())
def get_max_index(tensor: np.ndarray):
return tensor.argmax().item()
批式任务的运行结果为:

-------------------------------- Metrics: -------------------------------- Accuracy:0.9903 Macro F1:0.9902 Micro F1:0.9903 Kappa:0.9892 |Pred\Real| 9| 8| 7|...| 2| 1| 0| |---------|---|---|----|---|----|----|---| | 9|992| 1| 4|...| 0| 0| 0| | 8| 2|965| 1|...| 0| 1| 1| | 7| 5| 2|1012|...| 2| 0| 1| | ...|...|...| ...|...| ...| ...|...| | 2| 2| 4| 9|...|1030| 3| 2| | 1| 0| 0| 2|...| 0|1128| 0| | 0| 0| 2| 0|...| 0| 0|973|
25.5.3 流式任务中使用PyTorch模型
使用TorchModelPredictStreamOp组件,可以加载PyTorch模型进行批式预测。关于该组件的详细说明参见Alink文档 https://www.yuque.com/pinshu/alink_doc/torchmodelpredictstreamop .
使用PyTorch模型前,还需要将输入数据列的类型转换为Tensor格式,可以使用VectorToTensorStreamOp组件。具体代码如下所示:
AkSourceStreamOp()\
.setFilePath(Chap13_DATA_DIR + Chap13_DENSE_TEST_FILE)\
.link(\
VectorToTensorStreamOp()\
.setTensorDataType("float")\
.setTensorShape([1, 1, 28, 28])
.setSelectedCol("vec")\
.setOutputCol("tensor")\
.setReservedCols(["label"])
)\
.link(\
TorchModelPredictStreamOp()\
.setModelPath(
"https://alink-release.oss-cn-beijing.aliyuncs.com/data-files/mnist_model_pytorch.pt")\
.setSelectedCols(["tensor"])\
.setOutputSchemaStr("output_1 FLOAT_TENSOR")
)\
.link(\
UDFStreamOp()\
.setFunc(get_max_index)\
.setSelectedCols(["output_1"])\
.setOutputCol("pred")
)\
.sample(0.001)\
.print()
StreamOperator.execute()运行结果为:
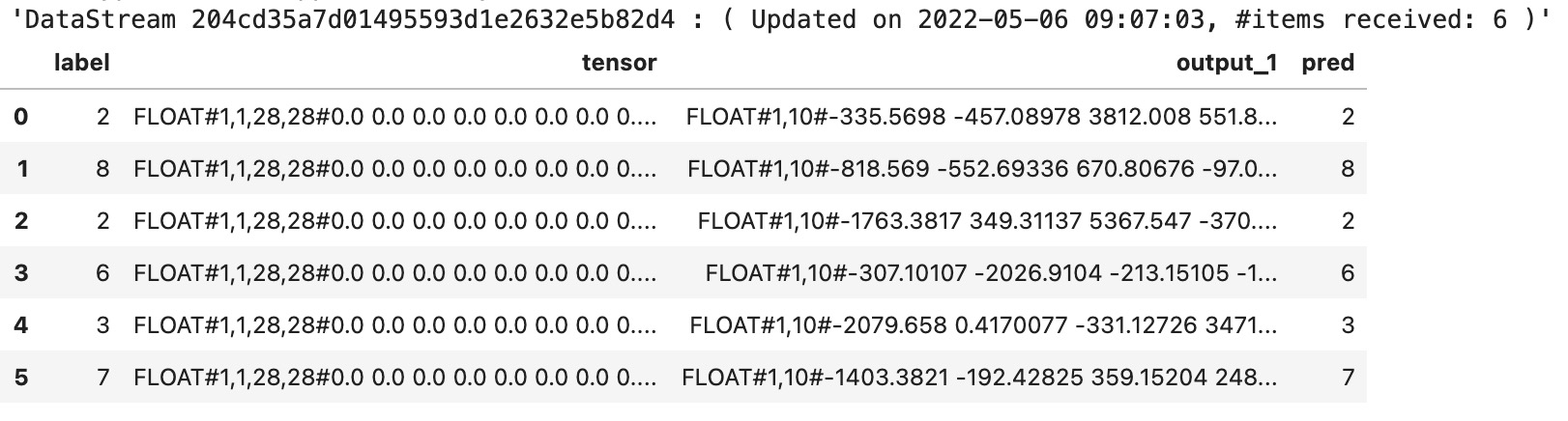
25.5.4 Pipeline中使用PyTorch模型
学习了如何在批式任务和流式任务中使用PyTorch模型,我们很容易在Pipeline中使用PyTorch模型进行预测,只要将其中的批式/流式组件对应到Pipeline组件即可。具体代码如下:
PipelineModel(\
VectorToTensor()\
.setTensorDataType("float")\
.setTensorShape([1, 1, 28, 28])\
.setSelectedCol("vec")\
.setOutputCol("tensor")\
.setReservedCols(["label"]),
TorchModelPredictor()\
.setModelPath(
"https://alink-release.oss-cn-beijing.aliyuncs.com/data-files/mnist_model_pytorch.pt")\
.setSelectedCols(["tensor"])\
.setOutputSchemaStr("output_1 FLOAT_TENSOR")
).save(Chap13_DATA_DIR + PIPELINE_PYTORCH_MODEL, True)
BatchOperator.execute()
PipelineModel\
.load(Chap13_DATA_DIR + PIPELINE_PYTORCH_MODEL)\
.transform(\
AkSourceStreamOp()\
.setFilePath(Chap13_DATA_DIR + Chap13_DENSE_TEST_FILE)
)\
.link(\
UDFStreamOp()\
.setFunc(get_max_index)\
.setSelectedCols(["output_1"])\
.setOutputCol("pred")
)\
.sample(0.001)\
.print()
StreamOperator.execute()运行结果为:
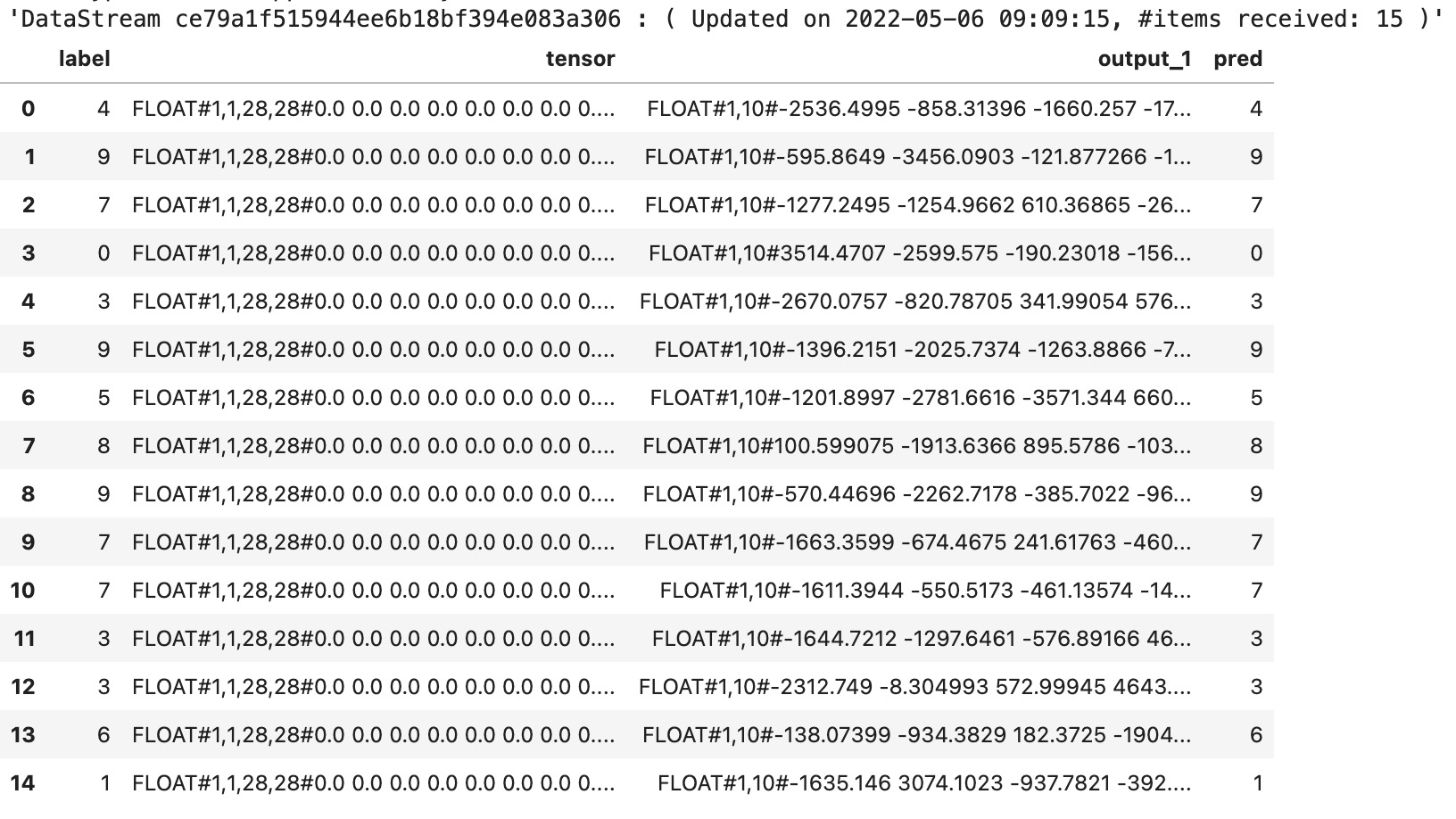
25.5.5 LocalPredictor中使用PyTorch模型
除了通过Alink任务使用PyTorch模型,也可以使用LocalPredictor进行嵌入式预测。示例代码如下,首先从数据集中抽取一行数据,输入数据的SchemaStr为“vec string, label int”;然后通过导入上一节保存的Pipeline模型,并设置输入数据的SchemaStr,得到LocalPredictor类型的实例localPredictor;如果不确定预测结果各列的含义,可以打印输出localPredictor的OutputSchema;使用localPredictor的map方法获得预测结果。
source = AkSourceBatchOp().setFilePath(Chap13_DATA_DIR + Chap13_DENSE_TEST_FILE) print(source.getSchemaStr()) df = source.firstN(1).collectToDataframe() row = [df.iat[0,0], df.iat[0,1].item()] localPredictor = LocalPredictor(Chap13_DATA_DIR + PIPELINE_PYTORCH_MODEL, "vec string, label int") print(localPredictor.getOutputSchemaStr()) r = localPredictor.map(row) print(str(r[0]) + " | " + str(r[2]))
运行结果为:
vec VARCHAR, label INT label INT, tensor ANY<com.alibaba.alink.common.linalg.tensor.FloatTensor>, output_1 ANY<com.alibaba.alink.common.linalg.tensor.FloatTensor> 2 | FloatTensor(1,10) [[500.5041 499.77554 4562.968 ... -759.00934 -1826.2468 -2071.0444]]