- Alink权威指南:机器学习实例入门(Python版)
- Alink教程(Python版)目录
- Alink教程(Python版)代码的运行攻略
- Alink教程(Python版)的数据和资料链接
- 第1章 Alink快速上手
- 第1.1节 Alink是什么
- 第1.2节 免费下载、安装
- 第1.2.1节 PyAlink快速开始
- 第1.2.1.1节 PyAlink安装准备——MacOS
- 第1.2.1.2节 PyAlink安装准备——阿里云服务器
- 第1.2.1.3节 如何安装最新版本PyAlink?
- 第1.2.1.4节 PyAlink的版本查询、卸载旧版本
- 第1.2.2节 在 Flink 集群上运行 PyAlink 任务
- 第1.3节 Alink的功能
- 第1.4节 关于数据和代码
- 第1.5节 简单示例
- 第2章 系统概况与核心概念
- 第2.1节 基本概念
- 第2.2节 批式任务与流式任务
- 第2.3节 Alink=A+link
- 第2.4节 Pipeline与PipelineModel
- 第2.5节 触发Alink任务的执行
- 第2.5.1节 批式任务打印输出中间结果
- 第2.6节 模型信息显示
- 第2.7节 文件系统与数据库
- 第2.8节 Schema String
- 第3章 文件系统与数据文件
- 第3.2.4节 读取Parquet文件格式数据
- 第3.2.5节 定时输出流式数据
- 第3.2.6节 读取分区格式数据
- 第4章 数据库与数据表
- 第4.5节 Alink连接Kafka数据源
- 第5章 支持Flink SQL
- 第5.3.4节 Flink与Alink的数据转换
- 第6章 用户定义函数(UDF/UDTF)
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第10章 特征的转化
- 第11章 构造新特征
- 第12章 从二分类到多分类
- 第13章 常用的多分类算法
- 第14章 在线学习
- 第15章 回归的由来
- 第16章 常用的回归算法
- 第17章 常用的聚类算法
- 第18章 批式与流式聚类
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第22章 单词向量化
- 第23章 情感分析
- 第23.5节 中文情感分析示例
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 第25.1节 深度学习组件简介
- 第25.1.1节 深度学习功能概览
- 第25.1.2节 KerasSequential组件
- 第25.1.3节 深度学习相关插件的下载
- 第25.2节 手写识别MNIST
- 第25.3节 深度回归算法
- 第25.4节 运行TensorFlow模型
- 第25.5节 运行PyTorch模型
- 第25.6节 使用自定义 TensorFlow 脚本
- 第25.7节 运行ONNX模型
- 第26章 图像识别
- 第26.1节 数据准备
- 第26.2节 构造二分类模型
- 第26.3节 使用TF Hub模型
- 第1章 Alink快速上手
- 在Flink集群部署Alink
- 在易用性方面的小技巧
- 流式组件输出数据的显示(基于Jupyter环境)
- Alink插件下载器
- 第2章 系统概况与核心概念
- Failed to load BLAS警告——Mac OS上解决方法
- 在Linux,Mac下定时执行Alink任务
- Failed to load BLAS警告——Linux上解决方法
- 第3章 文件系统与数据文件
- 第4章 数据库与数据表
- Catalog中设置数据库分区【Alink使用技巧】
- 在MacOS上搭建Kafka
- 在Windows上搭建Kafka
- 第5章 支持Flink SQL
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第11章 构造新特征
- GBDT+LR 一体化模型训练与预测
- GBDT+FM 一体化模型训练及预测
- 第13章 常用的多分类算法
- 第14章 在线学习 Ftrl Demo
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 基于图算法实现金融风控
- 如何使用Alink时间序列算法?
- 如何使用Alink窗口特征生成?
第2.4节 Pipeline与PipelineModel
Alink提供了Pipeline/PipelineModel,其在功能和使用方式上与Scikit-learn和SparkML的Pipeline/PipelineModel类似。保持训练和预测过程中数据处理的一致性,这样调用过程清晰、简练,也降低了用户的学习成本。Alink Pipeline/PipelineModel与批式/流式组件(BatchOperator/ StreamOperator)一样,将Flink Table作为计算输入和输出结果的数据类型。
Scikit-learn和SparkML的Pipeline是针对批式数据的训练和预测设计的。Alink不仅支持批式数据的训练和预测,也支持将批式训练出的模型用于预测流式数据。
2.4.1 概念和定义
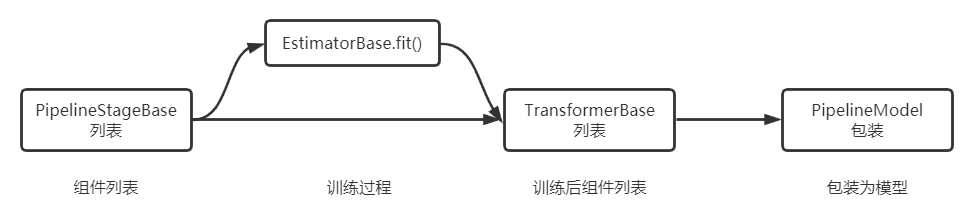
管道(Pipeline)的概念源于Scikit-learn。可以将数据处理的过程看成数据在“管道”中流动。管道分为若干个阶段(PipelineStage),数据每通过一个阶段就发生一次变换,数据通过整个管道,也就依次经历了所有变换。
如果要在管道中加入分类器,对数据进行类别预测,就涉及模型的训练和预测,这需要分两个步骤完成。所以,管道也会被细分为管道定义与管道模型(PipelineModel)。在管道定义中,每个PipelineStage会按其是否需要进行模型训练,分为估计器(Estimator)和转换器(Transformer)。随后,可以对其涉及模型的部分,即对估计器(Estimator)进行估计,从而得到含有模型的转换器。该转换器被称为Model,并用Model替换相应的估计器,从而每个阶段都可以直接对数据进行处理。我们将该Model称为PipelineModel。
上面介绍了几个概念,用图形表示它们之间的关系如下:
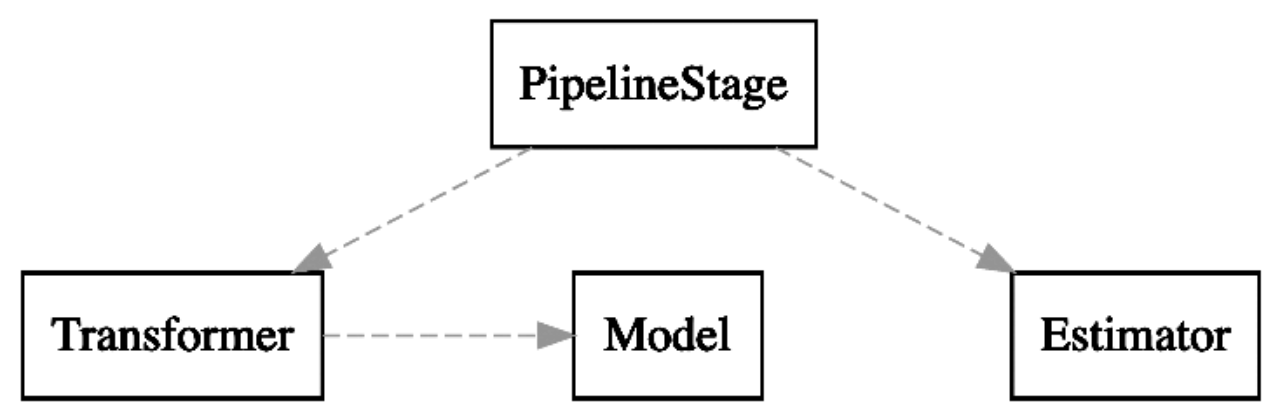
- 转换器(Transformer):Pipeline中的处理模块,用于处理Table。输入的是待处理的数据,输出的是处理结果数据。比如,向量归一化是一个常用的数据预处理操作。它就是一个转换器,输入向量数据,输出的数据仍为向量,但是其范数为1。
- Model:派生于转换器(Transformer)。其可以存放计算出来的模型,用来进行模型预测。其输入的是预测所需的特征数据,输出的是预测结果数据。
- 估计器(Estimator):估计器是对输入数据进行拟合或训练的模型计算模块,输出适合当前数据的转换器,即模型。输入的是训练数据,输出的是Model。
Pipeline与PipelineModel构成了完整的机器学习处理过程,可以分为三个子过程:定义过程,模型训练过程,数据处理过程。
- 定义过程:按顺序罗列Pipeline所需的各个阶段。Pipeline由若干个Transformer和Estimator构成,按用户指定的顺序排列,并在逻辑上依次执行。
- 模型训练过程:使用Pipeline的fit方法,对Pipeline中的Estimator进行训练,得到相应的Model。Pipeline执行fit方法后得到的结果是PipelineModel。
- 数据处理过程:该过程指的是通过PipelineModel直接处理数据。
比如,LR分类算法作为一个Estimator,可以在构建Pipleline的时候进行定义,之后在fit的过程中,会使用LR的训练算法,得到LR model,并将其作为整个PipelineModel的一部分;在使用PipelineModel处理数据时,会相应地调用LR算法的预测部分。
2.4.2 深入介绍
以使用朴素贝叶斯算法进行多分类为例,演示三个经典场景:批式训练、批式预测与流式预测。为了更好地体现它们之间的关联,我们用一张图表示了出来,如下图所示。
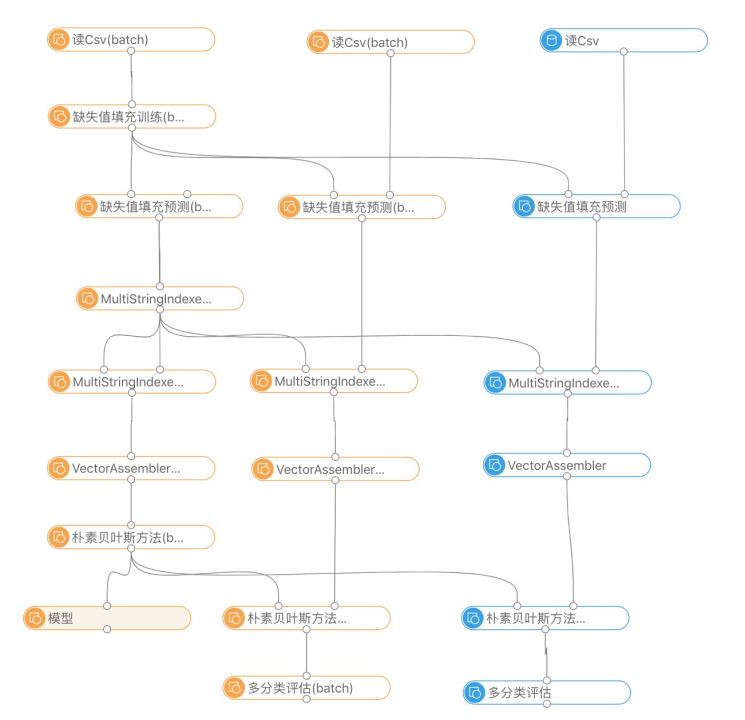
此图有如下特点:
(1)左边这列组件展示了批式训练的流程,中间那列组件展示了批式预测的流程,右边那列组件展示了流式预测的流程。
(2)训练和预测都经历了四个阶段:缺失值填充、MultiStringIndexer(将字符串数据用索引值替换)、VectorAssembler(将各数据字段组装为向量)、使用朴素贝叶斯算法进行训练/预测。
(3)在VectorAssembler阶段,运行时不需要额外的信息。在批式训练、批式预测和流式预测的过程中,组件均可直接使用。
(4)除VectorAssembler外的三个阶段,都需要对整体数据进行扫描或者迭代训练,得到模型后,才能处理(模型预测)数据。训练过程需要拿到所有的模型,缺失值填充和MultiStringIndexer阶段需要在得到模型后,对当前数据进行预测,将预测结果数据传给后面的阶段。
上面的四个阶段分别对应四个PipelineStage,这些PipelineStage构成了Pipeline。对应的代码如下:
pipeline = Pipeline()\
.add(
Imputer()\
.setSelectedCols("...")\
.setStrategy('VALUE')\
.setFillValue("null")
)\
.add(
MultiStringIndexer()\
.setSelectedCols("...")
)\
.add(
VectorAssembler()\
.setSelectedCols("...")\
.setOutputCol("vec")
)\
.add(
NaiveBayesTextClassifier()\
.setVectorCol("vec")\
.setLabelCol("label")\
.setPredictionCol("pred")
);Pipeline可多次复用,不同的训练数据通过同样的流程可得到不同的模型:
trainData1 = CsvSourceBatchOp() trainData2= CsvSourceBatchOp() model = pipeline.fit(trainData1) model2 = pipeline.fit(trainData2)
得到的PipelineModel可重复应用于不同的预测数据:
predictData1= CsvSourceBatchOp() predictData2= CsvSourceBatchOp() predict1 = model.transform(predictData1) predict2 = model.transform(predictData2)
PipelineModel可以无区别地应用于批式预测和流式预测:
batchData = CsvSourceBatchOp() streamData= CsvSourceStreamOp() predictBatch = model.transform(batchData) predictStream = model.transform(streamData)
从PipelineModel可以得到用于本地预测的LocalPredictor,直接嵌入Java应用服务:
inputSchemaStr = "..." localPredictor = model.collectLocalPredictor(inputSchemaStr) inputRow = [ ... ] pred = localPredictor.map(inputRow)
2.4.3 另一个角度
简单来讲, 预处理、特征工程、机器学习等组件可加载进pipeline进行训练预测,Pipeline也可以接Operator,
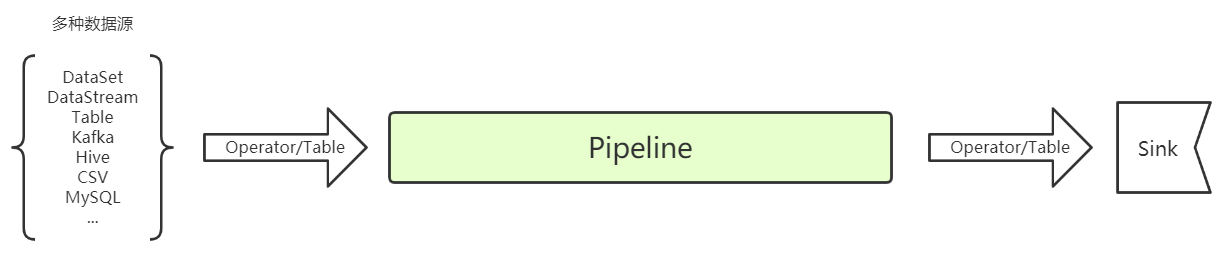
图片来源: https://www.cnblogs.com/liziof/p/13596480.html
Pipeline结构如下,