- Alink权威指南:机器学习实例入门(Python版)
- Alink教程(Python版)目录
- Alink教程(Python版)代码的运行攻略
- Alink教程(Python版)的数据和资料链接
- 第1章 Alink快速上手
- 第1.1节 Alink是什么
- 第1.2节 免费下载、安装
- 第1.2.1节 PyAlink快速开始
- 第1.2.1.1节 PyAlink安装准备——MacOS
- 第1.2.1.2节 PyAlink安装准备——阿里云服务器
- 第1.2.1.3节 如何安装最新版本PyAlink?
- 第1.2.1.4节 PyAlink的版本查询、卸载旧版本
- 第1.2.2节 在 Flink 集群上运行 PyAlink 任务
- 第1.3节 Alink的功能
- 第1.4节 关于数据和代码
- 第1.5节 简单示例
- 第2章 系统概况与核心概念
- 第2.1节 基本概念
- 第2.2节 批式任务与流式任务
- 第2.3节 Alink=A+link
- 第2.4节 Pipeline与PipelineModel
- 第2.5节 触发Alink任务的执行
- 第2.5.1节 批式任务打印输出中间结果
- 第2.6节 模型信息显示
- 第2.7节 文件系统与数据库
- 第2.8节 Schema String
- 第3章 文件系统与数据文件
- 第3.2.4节 读取Parquet文件格式数据
- 第3.2.5节 定时输出流式数据
- 第3.2.6节 读取分区格式数据
- 第4章 数据库与数据表
- 第4.5节 Alink连接Kafka数据源
- 第5章 支持Flink SQL
- 第5.3.4节 Flink与Alink的数据转换
- 第6章 用户定义函数(UDF/UDTF)
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第10章 特征的转化
- 第11章 构造新特征
- 第12章 从二分类到多分类
- 第13章 常用的多分类算法
- 第14章 在线学习
- 第15章 回归的由来
- 第16章 常用的回归算法
- 第17章 常用的聚类算法
- 第18章 批式与流式聚类
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第22章 单词向量化
- 第23章 情感分析
- 第23.5节 中文情感分析示例
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 第25.1节 深度学习组件简介
- 第25.1.1节 深度学习功能概览
- 第25.1.2节 KerasSequential组件
- 第25.1.3节 深度学习相关插件的下载
- 第25.2节 手写识别MNIST
- 第25.3节 深度回归算法
- 第25.4节 运行TensorFlow模型
- 第25.5节 运行PyTorch模型
- 第25.6节 使用自定义 TensorFlow 脚本
- 第25.7节 运行ONNX模型
- 第26章 图像识别
- 第26.1节 数据准备
- 第26.2节 构造二分类模型
- 第26.3节 使用TF Hub模型
- 第1章 Alink快速上手
- 在Flink集群部署Alink
- 在易用性方面的小技巧
- 流式组件输出数据的显示(基于Jupyter环境)
- Alink插件下载器
- 第2章 系统概况与核心概念
- Failed to load BLAS警告——Mac OS上解决方法
- 在Linux,Mac下定时执行Alink任务
- Failed to load BLAS警告——Linux上解决方法
- 第3章 文件系统与数据文件
- 第4章 数据库与数据表
- Catalog中设置数据库分区【Alink使用技巧】
- 在MacOS上搭建Kafka
- 在Windows上搭建Kafka
- 第5章 支持Flink SQL
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第11章 构造新特征
- GBDT+LR 一体化模型训练与预测
- GBDT+FM 一体化模型训练及预测
- 第13章 常用的多分类算法
- 第14章 在线学习 Ftrl Demo
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 基于图算法实现金融风控
- 如何使用Alink时间序列算法?
- 如何使用Alink窗口特征生成?
第3.2.5节 定时输出流式数据
在实际应用中,我们常需要将某个时间间隔(1小时,5分钟,10秒等间隔)的数据输出到一个文件,该数据文件随后可以被放入批式处理、增量训练等流程。
Alink提供了Export2FileSinkStreamOp组件,可以按指定的时间间隔,将数据保存到本地或远程的文件系统,每个数据文件都是AK格式。下面先介绍组件的参数:
- 参数WindowTime,设置间隔时间,以秒为单位,是必填参数。
- 参数FilePath,保存数据的文件夹名称,是必填参数
- 参数TimeCol,为时间列名称,是可选参数。如果没有设置该参数,会以流式任务运行节点的本地时间,计算间隔、输出数据文件。
- 参数OverwriteSink,为布尔型参数,默认值为false,即当发现参数“FilePath”指定的文件夹存在时会报错;如果设置为true,则会将文件夹中的文件全部删除,再写入新的数据文件。
�
�下面会以是否指定TimeCol参数,构建两个实例,帮助读者了解组件的功能。
�
�3.2.5.1 按本地时间定时输出流式数据
我们以MovieLens的一个评分数据为例,关于该数据的介绍,请参见24.3节,这里不再重复。使用TsvSourceStreamOp组件,可以直接从网络地址读取数据,具体代码如下:
source = TsvSourceStreamOp()\
.setFilePath("http://files.grouplens.org/datasets/movielens/ml-100k/u.data")\
.setSchemaStr("user_id long, item_id long, rating float, ts long")\
.link(
UDFStreamOp()\
.setFunc(from_unix_timestamp)\
.setSelectedCols(["ts"])\
.setOutputCol("ts")
)其中用户自定义函数FromUnixTimestamp的定义如下,该函数用于将原始数据中的long型表示时间的数据转换为Timestamp格式。
import datetime
@udf(input_types=[DataTypes.BIGINT()], result_type=DataTypes.TIMESTAMP(3))
def from_unix_timestamp(ts):
return datetime.datetime.fromtimestamp(ts)然后,将流式source连接Export2FileSinkStreamOp组件,并设置参数,具体代码如下,这里没有设置TimeCol参数,意味着组件会按本地时间进行数据保存,并按WindowTime参数的设置,每隔5秒保存一次文件。
source.link(
Export2FileSinkStreamOp()\
.setFilePath(LOCAL_DIR + "with_local_time")\
.setWindowTime(5)\
.setOverwriteSink(True)
)我们还连接了一个流式的Sink组件,用于准备后面的实验,具体代码如下。
source.link(
AkSinkStreamOp()\
.setFilePath(LOCAL_DIR + "ratings.ak")\
.setOverwriteSink(True)
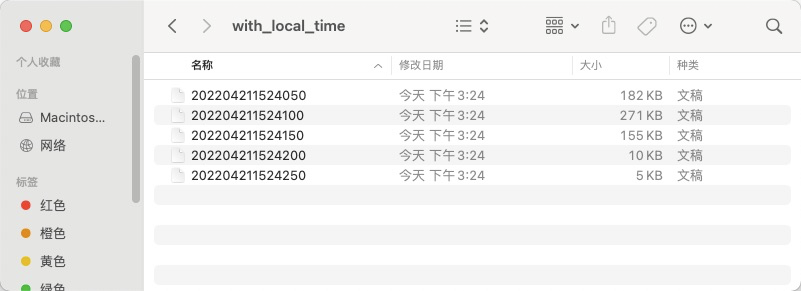
)执行流式任务,我们看到新建了名称为"with_local_time"的文件夹,具体内容详见下面的截图。其中包含了5个文件,都是AK格式,文件名是以间隔区间的结束时间点命名的,譬如:“202204211524050”对应时间:2022年4月21日15:24:05.0
最后,再做个简单的验证,统计一下"with_local_time"文件夹下的数据,详细代码如下:
AkSourceBatchOp()\
.setFilePath(LOCAL_DIR + "with_local_time")\
.lazyPrintStatistics("Statistics for data in the folder 'with_local_time' : ")
BatchOperator.execute()运行结果如下,共100000条数据,与原始数据集的条数相同。
Statistics for data in the folder 'with_local_time' : Summary: |colName| count|missing| sum| mean| variance|min| max| |-------|------|-------|--------|--------|-----------|---|----| |user_id|100000| 0|46248475|462.4848| 71083.249| 1| 943| |item_id|100000| 0|42553013|425.5301|109427.5525| 1|1682| | rating|100000| 0| 352986| 3.5299| 1.2671| 1| 5| | ts|100000| 0| NaN| NaN| NaN|NaN| NaN|
�3.2.5.2 按数据的时间列,定时输出流式数据
在实验前,先做一个数据准备工作,ratings.ak中的各条数据,从其ts时间列来看,几乎是随机分布在数据集中,我们相对其进行排序,并存入ratings_ordered.ak文件。具体代码如下:
AkSourceBatchOp()\
.setFilePath(LOCAL_DIR + "ratings.ak")\
.orderBy("ts", 1000000)\
.lazyPrintStatistics("Statistics for data in the file 'ratings.ak' : ")\
.link(
AkSinkBatchOp()\
.setFilePath(LOCAL_DIR + "ratings_ordered.ak")\
.setOverwriteSink(True)
)
BatchOperator.execute()�
以流的方式读入准备好的数据,然后连接Export2FileSinkStreamOp组件,设置时间列为 ts 列,并设置时间间隔为3600X24秒,即1天。具体代码如下:
AkSourceStreamOp()\
.setFilePath(LOCAL_DIR + "ratings_ordered.ak")\
.link(
Export2FileSinkStreamOp()\
.setFilePath(LOCAL_DIR + "with_ts_time")\
.setTimeCol("ts")\
.setWindowTime(3600 * 24)\
.setOverwriteSink(True)
)
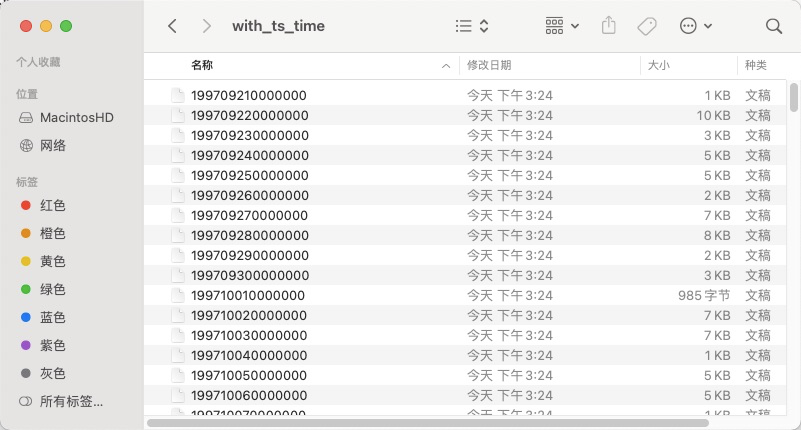
StreamOperator.execute()访问"with_local_time"文件夹,查看运行结果,具体内容详见下面的截图,每个文件保存了一天的数据。
再读取数据,进行深入验证,一方面读取整个文件夹的数据,进行统计;另一方面,选择一个数据文件,打印输出,查看起时间列的信息。详细代码如下:
AkSourceBatchOp()\
.setFilePath(LOCAL_DIR + "with_ts_time")\
.lazyPrintStatistics("Statistics for data in the folder 'with_ts_time' : ")
AkSourceBatchOp()\
.setFilePath(LOCAL_DIR + "with_ts_time" + os.sep + "199709210000000")\
.print()运行结果如下,"with_local_time"文件夹下包含100000条数据,而且各项统计指标也与 ratings.ak 的也相同;
Statistics for data in the folder 'with_ts_time' : Summary: |colName| count|missing| sum| mean| variance|min| max| |-------|------|-------|--------|--------|-----------|---|----| |user_id|100000| 0|46248475|462.4848| 71083.249| 1| 943| |item_id|100000| 0|42553013|425.5301|109427.5525| 1|1682| | rating|100000| 0| 352986| 3.5299| 1.2671| 1| 5| | ts|100000| 0| NaN| NaN| NaN|NaN| NaN|
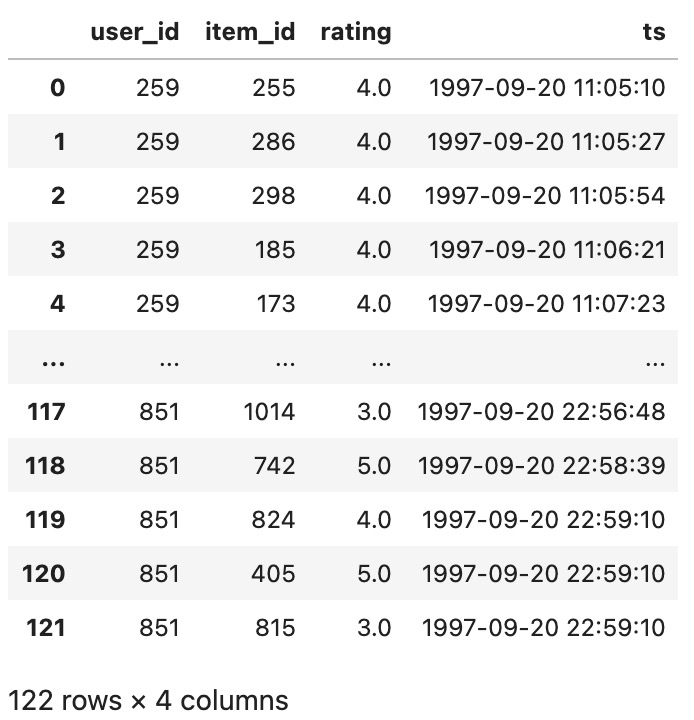
文件199709210000000中的各数据显示如下图所示,都为1997-09-20的,也符合预期。
3.2.5.3 输出带分区的数据
在文件系统上存储长期的数据,经常将时间作为分区名称,通过选择分区名称,选择部分数据进行操作。Export2FileSinkStreamOp组件可以通过指定参数PartitionsFormat来定义输出的分区格式。如下面代码所示,"year=yyyy/month=MM/day=dd"表明输出三级文件夹,第一级文件夹的名称以“year=”开头,后面是4位的年份信息;第二级文件夹的名称以“month=”开头,后面是2位的月份信息,譬如:1月表示为“01”,12月表示为“12”;第三级文件夹的名称以“day=”开头,后面是2位的天信息,譬如:5号表示为“05”,31号表示为“31”。
AkSourceStreamOp()\
.setFilePath(LOCAL_DIR + "ratings_ordered.ak")\
.link(
Export2FileSinkStreamOp()\
.setFilePath(LOCAL_DIR + "data_with_partitions")\
.setTimeCol("ts")\
.setWindowTime(3600 * 24)\
.setPartitionsFormat("year=yyyy/month=MM/day=dd")\
.setOverwriteSink(True)
)
StreamOperator.execute()运行结束后,我们可以在文件夹看到如下结构: