- Alink权威指南:机器学习实例入门(Java版)
- Alink教程(Java版)目录
- Alink教程(Java版)代码的运行攻略
- 下载部分示例数据的Java代码
- Alink教程(Java版)的数据和资料链接
- 第1章 Alink快速上手
- 第1.1节 Alink是什么
- 第1.2节 免费下载、安装
- 第1.2.1节 使用 Maven 快速构建 Alink Java 项目
- 第1.2.2节 在集群上运行 Alink Java 任务
- 第1.3节 Alink的功能
- 第1.4节 关于数据和代码
- 第2章 系统概况与核心概念
- 第2.1节 基本概念
- 第2.2节 批式任务与流式任务
- 第2.3节 Alink=A+link
- 第2.4节 Pipeline与PipelineModel
- 第2.5节 触发Alink任务的执行
- 第2.5.1节 批式任务打印输出中间结果
- 第2.6节 模型信息显示
- 第2.7节 文件系统与数据库
- 第2.8节 Schema String
- 第3章 文件系统与数据文件
- 第3.2.4节 读取Parquet文件格式数据
- 第3.2.5节 定时输出流式数据
- 第3.2.6节 读取分区格式数据
- 第4章 数据库与数据表
- 第4.5节 Alink连接Kafka数据源
- 第5章 支持Flink SQL
- 第5.3.4节 Flink与Alink的数据转换
- 第6章 用户定义函数(UDF/UDTF)
- 第7章 基本数据处理
- 第7.6节 数据列的选择
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第10章 特征的转化
- 第11章 构造新特征
- 第12章 从二分类到多分类
- 第13章 常用多分类算法
- 第14章 在线学习
- 第15章 回归的由来
- 第16章 常用回归算法
- 第17章 常用聚类算法
- 第18章 批式与流式聚类
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第22章 单词向量化
- 第23章 情感分析
- 第23.5节 中文情感分析示例
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 第25.1节 深度学习组件简介
- 第25.1.1节 深度学习功能概览
- 第25.1.2节 KerasSequential组件
- 第25.1.3节 深度学习相关插件的下载
- 第25.2节 手写识别MNIST
- 第25.3节 深度回归算法
- 第25.4节 运行TensorFlow模型
- 第25.5节 运行PyTorch模型
- 第25.6节 使用自定义 TensorFlow 脚本
- 第25.7节 运行ONNX模型
- 第26章 图像识别
- 第26.1节 数据准备
- 第26.2节 构造二分类模型
- 第26.3节 使用TF Hub模型
- 第27章 语音识别
- 第27.1节 数据准备
- 第27.2节 提取MFCC特征
- 第27.3节 情绪识别
- 第27.4节 录音人识别
- 第28章 深度文本分析
- 第28.1节 中文情感分析
- 第28.2节 BERT文本向量化
- 第28.3节 BERT文本分类器
- 第29章 模型流
- 第29.1节 “看到”模型流
- 第29.2节 批式训练与模型流
- 第29.3节 流式预测与LocalPredictor
- 第29.4节 PipelineModel构成的模型流
- 第29.5节 线性模型的增量训练
- 第29.6节 模型流的过滤
- 第30章 多并行与多线程
- 第30.1节 并行度(Parallelism)
- 第30.2节 多线程(Multi-threads)
- 第30.3节 LocalPredictor使用线程池
- 第31章 图嵌入表示GraphEmbedding
- 第31.1节 算法简介
- 第31.2节 示例数据
- 第31.3节 计算Embedding
- 第31.4节 查看Embedding
- 第31.5节 分类示例
- 第31.6节 改变训练参数
- 第1章 Alink快速上手
- 在Flink集群部署Alink
- 在易用性方面的小技巧
- 流式组件输出数据的显示(基于Jupyter环境)
- Alink插件下载器
- 第2章 系统概况与核心概念
- Failed to load BLAS警告——Mac OS上解决方法
- 在Linux,Mac下定时执行Alink任务
- Failed to load BLAS警告——Linux上解决方法
- 第3章 文件系统与数据文件
- 第4章 数据库与数据表
- Catalog中设置数据库分区【Alink使用技巧】
- 在MacOS上搭建Kafka
- 在Windows上搭建Kafka
- 第5章 支持Flink SQL
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第11章 构造新特征
- GBDT+LR 一体化模型训练与预测
- GBDT+FM 一体化模型训练及预测
- 第13章 常用的多分类算法
- 第14章 在线学习 Ftrl Demo
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 基于图算法实现金融风控
- 如何使用Alink时间序列算法?
- 如何使用Alink窗口特征生成?
第2.3节 Alink=A+link
由前面关于批式任务与流式任务的介绍可知,批式任务与流式任务的数据计算及处理操作都发生在组件中,各组件间的连线就是数据的通路。批式任务和流式任务中有关组件与连接的描述是通用的。
Alink定义了组件的抽象基类AlgoOperator,规范了组件的基本行为。由AlgoOperator派生出了两个基类:用于批式计算及处理场景的批式算法组件(BatchOperator)和用于流式计算及处理场景的流式算法组件(StreamOperator)。
组件间的连接是通过定义link方法实现的,比如,组件algoA的输出是组件algoB的输入,而组件algoB的输出又是组件algoC的输入,则可以通过组件的link方法表示:
algoA.link(algoB).link(algoC)
Alink的名称可以从这个角度进行解读:“Alink=A+link”。这里的A代表Alink的全部算法组件,其都是由抽象基类AlgoOperator派生出来的;link是AlgoOperator各派生组件间的连接方法。
2.3.1 BatchOperator和StreamOperator
由算法组件的抽象基类(AlgoOperator)派生出两个基类:批式算法组件(BatchOperator,或称为批式处理组件、批式组件)和流式算法组件(StreamOperator,或称为流式处理组件、流式组件),它们的UML类图如下图所示。
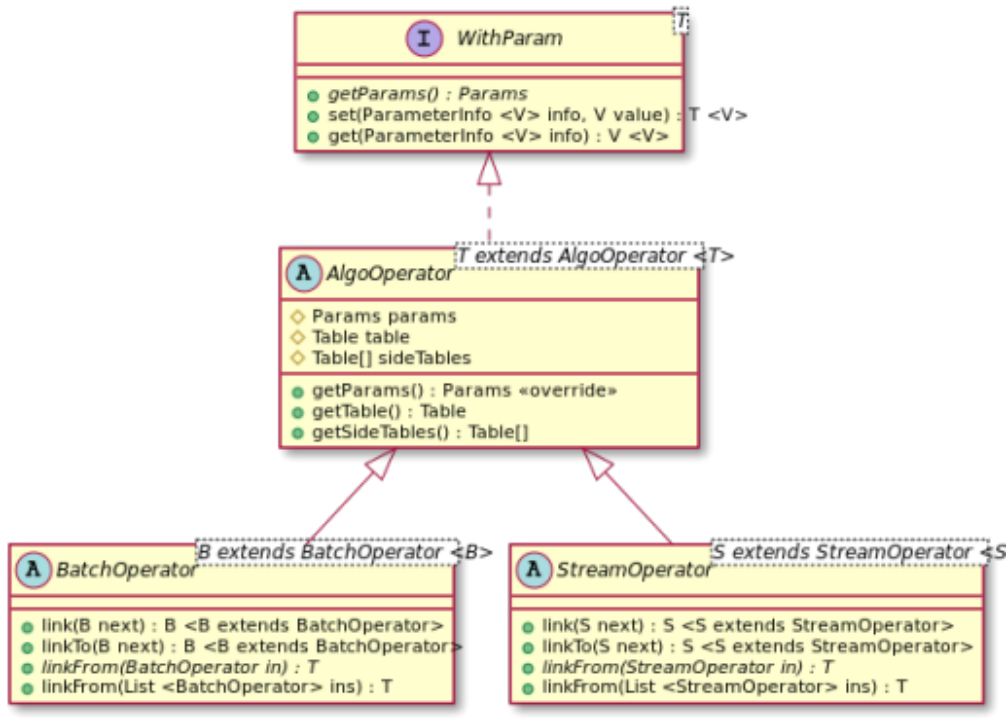
由UML类图,可以看到如下信息:
- WithParam定义了参数设定和获取的接口。
- 抽象基类AlgoOperator中有Params类型的成员变量params,并实现了参数设定和获取的接口;还定义了Table类型的变量table,以及Table类型数组的变量sideTables,用来存放算法的结果,并提供方法供后续组件读取。
- AlgoOperator下面有2个派生泛型基类:BatchOperator(批式算法组件)和StreamOperator(流式算法组件)。可以看到,这两种算法组件都支持link的操作;但批式算法组件只能连接一个或多个批式算法组件,流式算法组件只能连接一个或多个流式算法组件。对于需要批式数据和流式数据混合处理的算法,我们会将其作为流式算法组件,一般会将批式数据通过流式算法组件的构造函数传入。
Alink将每个批式操作定义为一个批式组件(BatchOperator),每个批式组件在命名上都以“BatchOp”为后缀;同样,将每个流式操作定义为一个流式组件(StreamOperator),每个流式组件在命名上都以“StreamOp”为后缀。
通过这样的定义,批式任务和流式任务都可以用相同的方式进行描述,这样就可以大大降低批式任务和流式任务转换的代价。若需要将一个批式任务改写为流式任务,只需要将批式组件后面的“BatchOp”后缀变为“StreamOp”,相应的link操作便可转换为针对流式数据的操作。也正是因为Alink的批式组件和流式组件有如此密切的联系,所以才能将机器学习的管道(Pipeline)操作推广到流式场景。
算法的输入数据,在大多数情况下可以用一个表(Table)表示,但也有不少情况下需要用多个表(Table)才能表示。比如Graph数据,一般包括Edge Table和Node Table,这两个表在一起才是完整的表示。算法的输出也是这样的情况。在大多数情况下可以用一个表(Table)表示,但也有不少情况下需要用多个表(Table)才能表示。比如,Graph操作的结果还是Graph,仍然需要用2个Table分别表示结果图中各条边和各个顶点的信息。自然语言方面的常用算法LDA(Latent Dirichlet Allocation)的计算结果为6个Table。其算法组件包含了一个Table类型的成员变量table,用来放置该组件的主输出结果(大多数情况下,算法计算的结果只有一个Table,输出到该变量即可)。该算法组件也定义了一个Table类型数组的变量sideTables,该变量用来存储在多表(Table)输出的情况下,除主表外的所有其他表。
2.3.2 link方式是批式算法/流式算法的通用使用方式
简单地说,link方式指的是在工作流中通过连线的方式,串接起不同的组件。link方式给我们带来的一个简化是,前序组件的产出结果可能比较复杂,比如描述的是一个机器学习模型,我们不必了解其细节、不必详细描述它,只要通过“link”的方式将两个组件建立连接,后面的组件即可通过该连接(link)来获取前序组件的处理结果数据、数据的列数,以及各列的名称和类型。
1. link、linkTo和linkFrom
连接(link)是有方向的,组件A连接组件B,即先执行组件A,然后将计算结果传给组件B继续执行,则组件间的关系可以通过以下三种方式表示:
- A.linkTo(B)
- B.linkFrom(A)
- A.link(B)
这里,可将link看作linkTo的简写。
关于两个组件A、B之间的连接(link)关系,很容易理解。在实际应用中,我们还会遇到更复杂的情况,但使用link方法仍可以轻松处理。
(1)一对多的情况
组件B1、B2、B3均需要组件A的计算结果,组件间的关系可以通过以下多种方式表示:
- A.linkTo(B1),A.linkTo(B2),A.linkTo(B3)
- A.link(B1),A.link(B2),A.link(B3)
- B1.linkFrom(A),B2.linkFrom(A),B3.linkFrom(A)
- A.linkTo(B1),A.link(B2),B3.linkFrom(A)
从上述表示方式上可以看出,表示方式可以很灵活。因为组件B1、B2、B3与组件A的关系是独立的,所以可以分别选用表示方式。
(2)多对一的情况
组件B同时需要组件A1、A2、A3的计算结果,表示方式只有一种:
B.linkFrom(A1, A2, A3)
即,linkFrom可以同时接入多个组件。
2. 深入理解
批式处理组件BatchOperator的相关代码如下:
public abstract class BatchOperator {
... ...
public BatchOperator link(BatchOperator f) {
return linkTo(f);
}
public BatchOperator linkTo(BatchOperator f) {
f.linkFrom(this);
return f;
}
abstract public BatchOperator linkFrom(BatchOperator in);
public BatchOperator linkFrom(List<BatchOperator> ins) {
if (null != ins && ins.size() == 1) {
return linkFrom(ins.get(0));
} else {
throw new RuntimeException("Not support more than 1 inputs!");
}
}
... ...
}流式处理组件StreamOperator的相关代码如下:
public abstract class StreamOperator {
... ...
public StreamOperator link(StreamOperator f) {
return linkTo(f);
}
public StreamOperator linkTo(StreamOperator f) {
f.linkFrom(this);
return f;
}
abstract public StreamOperator linkFrom(StreamOperator in);
public StreamOperator linkFrom(List <StreamOperator> ins) {
if (null != ins && ins.size() == 1) {
return linkFrom(ins.get(0));
} else {
throw new RuntimeException("Not support more than 1 inputs!");
}
}
... ...
}从上述代码中,我们可以看出link、linkTo与linkFrom的关系。首先看看link与linkTo的关系:
public BatchOperator link(BatchOperator f) {
return linkTo(f);
}
public StreamOperator link(StreamOperator f) {
return linkTo(f);
}显然,link等同于linkTo,可以将link看作linkTo的简写。
然后,我们再将注意力转向linkTo与linkFrom:
public BatchOperator linkTo(BatchOperator f) {
f.linkFrom(this);
return f;
}
public StreamOperator linkTo(StreamOperator f) {
f.linkFrom(this);
return f;
}显然,A.linkTo(B)等效于B.linkFrom(A),在linkTo组件具体实现时,只要实现linkFrom方法即可。
基类BatchOperator和StreamOperator均定义了输入参数为一个组件的抽象方法linkFrom,该方法需要继承类进行实现;抽象类BatchOperator和StreamOperator同时也实现了一个输入是组件列表的方法linkFrom,在组件列表中只含有一个组件的时候,该方法会调用前面的抽象方法linkFrom;在其他情况下,则会抛出异常。
在我们实现的组件中,大部分组件只支持输入一个组件,即只要实现输入参数为一个组件的抽象方法linkFrom就可以了;有的组件支持输入多个组件,则需要重载输入为组件列表的方法linkFrom,并将输入为一个组件的情况看作输入为算法列表时,列表中的组件个数为一个的情况。
2.3.3 link的简化
link组件是Alink的基本使用方式;但对于一些常用的功能,比如取前N条数据、随机采样、SQL SELECT、数据过滤等,Alink定义了相关的方法(方法内部的实现过程也是link相应的组件),这样代码写起来会更简练。
对比下面两段代码,执行的是同样的功能;但是很明显,右边的代码更简练,也更易懂:
source .link( new SelectBatchOp() .setClause("petal_width, category") ) .link( new FilterBatchOp() .setClause("category='Iris-setosa'") ) .link( new SampleBatchOp() .setRatio(0.3) ) .link( new FirstNBatchOp() .setSize(5) ) .print(); | source .select("petal_width, category") .filter("category='Iris-setosa'") .sample(0.3) .firstN(5) .print(); |
2.3.4 组件的主输出与侧输出
组件可能需要一个或多个输入,通过linkFrom方法便可将多个上游组件的输出连接到该组件。组件也会产生一个或多个输出。对大部分算法组件来说,结果只有一个数据表,输出是唯一的,但是有些算法组件会产生多个数据表。这时,就需要确认一个数据表作为主输出,其余数据表作为侧输出(Side Output)。
侧输出(Side Output)有两个重要方法:
- getSideOutputCount()获得该组件侧输出的个数。
- getSideOutput(int index)方法通过索引号获取具体的侧输出,每个侧输出是BatchOperator或者StreamOperator。
比如,我们在做机器学习实验的时候,经常要把原始数据分为训练集和测试集,数据划分组件就会对应两个输出:主输出为训练集;侧输出(Side Output)只有一个,即输出测试集。详细的例子可以参考7.2节