- Alink权威指南:机器学习实例入门(Java版)
- Alink教程(Java版)目录
- Alink教程(Java版)代码的运行攻略
- 下载部分示例数据的Java代码
- Alink教程(Java版)的数据和资料链接
- 第1章 Alink快速上手
- 第1.1节 Alink是什么
- 第1.2节 免费下载、安装
- 第1.2.1节 使用 Maven 快速构建 Alink Java 项目
- 第1.2.2节 在集群上运行 Alink Java 任务
- 第1.3节 Alink的功能
- 第1.4节 关于数据和代码
- 第2章 系统概况与核心概念
- 第2.1节 基本概念
- 第2.2节 批式任务与流式任务
- 第2.3节 Alink=A+link
- 第2.4节 Pipeline与PipelineModel
- 第2.5节 触发Alink任务的执行
- 第2.5.1节 批式任务打印输出中间结果
- 第2.6节 模型信息显示
- 第2.7节 文件系统与数据库
- 第2.8节 Schema String
- 第3章 文件系统与数据文件
- 第3.2.4节 读取Parquet文件格式数据
- 第3.2.5节 定时输出流式数据
- 第3.2.6节 读取分区格式数据
- 第4章 数据库与数据表
- 第4.5节 Alink连接Kafka数据源
- 第5章 支持Flink SQL
- 第5.3.4节 Flink与Alink的数据转换
- 第6章 用户定义函数(UDF/UDTF)
- 第7章 基本数据处理
- 第7.6节 数据列的选择
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第10章 特征的转化
- 第11章 构造新特征
- 第12章 从二分类到多分类
- 第13章 常用多分类算法
- 第14章 在线学习
- 第15章 回归的由来
- 第16章 常用回归算法
- 第17章 常用聚类算法
- 第18章 批式与流式聚类
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第22章 单词向量化
- 第23章 情感分析
- 第23.5节 中文情感分析示例
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 第25.1节 深度学习组件简介
- 第25.1.1节 深度学习功能概览
- 第25.1.2节 KerasSequential组件
- 第25.1.3节 深度学习相关插件的下载
- 第25.2节 手写识别MNIST
- 第25.3节 深度回归算法
- 第25.4节 运行TensorFlow模型
- 第25.5节 运行PyTorch模型
- 第25.6节 使用自定义 TensorFlow 脚本
- 第25.7节 运行ONNX模型
- 第26章 图像识别
- 第26.1节 数据准备
- 第26.2节 构造二分类模型
- 第26.3节 使用TF Hub模型
- 第27章 语音识别
- 第27.1节 数据准备
- 第27.2节 提取MFCC特征
- 第27.3节 情绪识别
- 第27.4节 录音人识别
- 第28章 深度文本分析
- 第28.1节 中文情感分析
- 第28.2节 BERT文本向量化
- 第28.3节 BERT文本分类器
- 第29章 模型流
- 第29.1节 “看到”模型流
- 第29.2节 批式训练与模型流
- 第29.3节 流式预测与LocalPredictor
- 第29.4节 PipelineModel构成的模型流
- 第29.5节 线性模型的增量训练
- 第29.6节 模型流的过滤
- 第30章 多并行与多线程
- 第30.1节 并行度(Parallelism)
- 第30.2节 多线程(Multi-threads)
- 第30.3节 LocalPredictor使用线程池
- 第31章 图嵌入表示GraphEmbedding
- 第31.1节 算法简介
- 第31.2节 示例数据
- 第31.3节 计算Embedding
- 第31.4节 查看Embedding
- 第31.5节 分类示例
- 第31.6节 改变训练参数
- 第1章 Alink快速上手
- 在Flink集群部署Alink
- 在易用性方面的小技巧
- 流式组件输出数据的显示(基于Jupyter环境)
- Alink插件下载器
- 第2章 系统概况与核心概念
- Failed to load BLAS警告——Mac OS上解决方法
- 在Linux,Mac下定时执行Alink任务
- Failed to load BLAS警告——Linux上解决方法
- 第3章 文件系统与数据文件
- 第4章 数据库与数据表
- Catalog中设置数据库分区【Alink使用技巧】
- 在MacOS上搭建Kafka
- 在Windows上搭建Kafka
- 第5章 支持Flink SQL
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第11章 构造新特征
- GBDT+LR 一体化模型训练与预测
- GBDT+FM 一体化模型训练及预测
- 第13章 常用的多分类算法
- 第14章 在线学习 Ftrl Demo
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 基于图算法实现金融风控
- 如何使用Alink时间序列算法?
- 如何使用Alink窗口特征生成?
第1.2.1节 使用 Maven 快速构建 Alink Java 项目
Alink支持发布到Maven Central,Java开发者通过Maven可以快速搭建Alink机器学习项目。本文将演示一个简单的构建方案,便于爱好者快速入门。
先说一下相关的环境,Windows系统,使用的Jave编辑器是 InterlliJ IDEA(Version 2019.3.2),Java SDK的版本为1.8。
第一步,创建项目
在InterlliJ IDEA中选择创建新项目,并选择Maven,如下图所示:
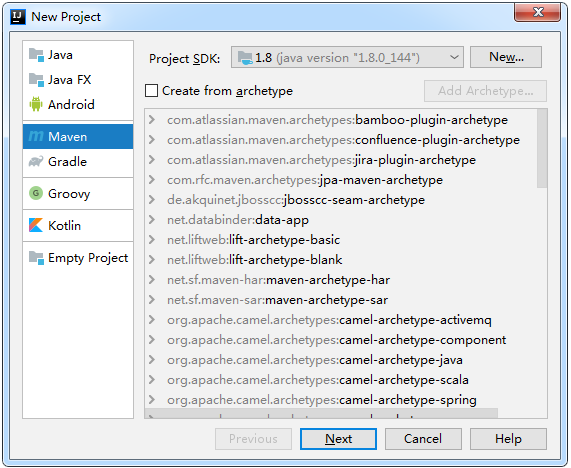
使用默认选项,不用勾选"Create from archetype",点击"Next"按钮,进入下图所示页面,这里只需填写Name项,其它内容会自动关联生成。
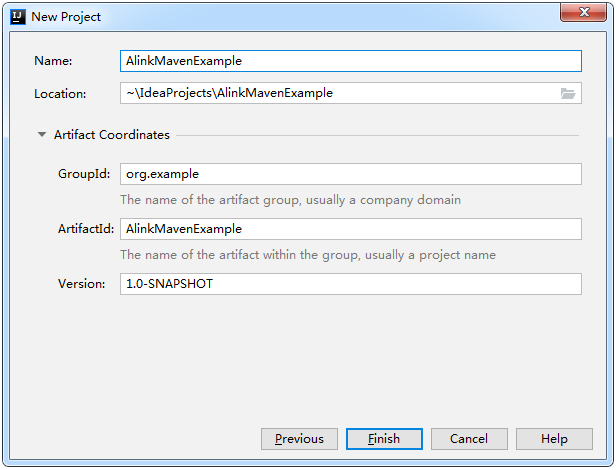
最后,点击"Finish"按钮,就完成了Maven工程的创建。
我们在InterlliJ IDEA编辑器中可以看到整个项目的结构如下:
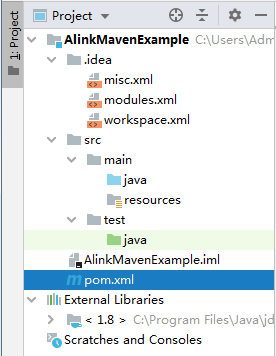
我们查看pom.xml,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>AlinkMavenExample</artifactId>
<version>1.0-SNAPSHOT</version>
</project>第二步,HelloAlink
在开始引入Alink相关jar包前,我们先进行一个小实验,运行简单的打印输出。在src -> main -> java下新建一个package: "org.example",再新建一个Java Class: "HelloAlink.java"
package org.example; public class HelloAlink { public static void main(String[] args) { System.out.println("Hello Alink!"); } }
运行该代码,结果正常打印。
然后,我们在看一下maven打包的情况,进入IDEA的Maven窗口,如下图所示
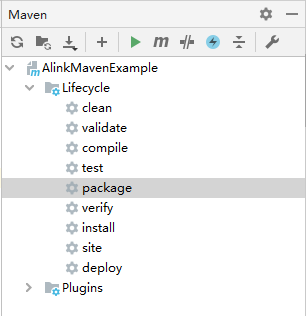
在Maven窗口中点击执行"package"操作,操作正常执行完成。在该项目文件夹的target子文件夹下可以看到打包出来的 AlinkMavenExample-1.0-SNAPSHOT.jar
第三步,修改POM文件,导入Alink相关jar包
这是本文中最重要的环节,在POM文件中设置Alink相关的dependency,从而在项目中可以使用Alink库函数。
可以从如下两个地址中找到Alink1.1.0的dependency设置:
其实,Alink提供了两个设置方案,分别针对Flink1.10和Flink1.9版本,这里我们选择针对Flink最新版本的方案。复制dependency项,并粘贴到POM的 <dependencies>...</dependencies>中,改动后的POM文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>AlinkMavenExample</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>com.alibaba.alink</groupId>
<artifactId>alink_core_flink-1.10_2.11</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.10.0</version>
</dependency>
</dependencies>
</project>这是IDEA会弹出小窗如下:

选择"Import Changes",需要等待一段时间,将所需的jar包下载到本地maven仓库。
第四步,构建运行
参考Alink的Java例子:
在当前项目中新建KMeansExample.java,保留当前的package路径`package org.example;`,将Alink例子中的其它代码直接复制过来。代码如下:
package org.example;
import com.alibaba.alink.operator.batch.BatchOperator;
import com.alibaba.alink.operator.batch.source.CsvSourceBatchOp;
import com.alibaba.alink.pipeline.Pipeline;
import com.alibaba.alink.pipeline.clustering.KMeans;
import com.alibaba.alink.pipeline.dataproc.vector.VectorAssembler;
/**
* Example for KMeans.
*/
public class KMeansExample {
public static void main(String[] args) throws Exception {
String URL = "https://alink-release.oss-cn-beijing.aliyuncs.com/data-files/iris.csv";
String SCHEMA_STR = "sepal_length double, sepal_width double, petal_length double, petal_width double, category string";
BatchOperator data = new CsvSourceBatchOp().setFilePath(URL).setSchemaStr(SCHEMA_STR);
VectorAssembler va = new VectorAssembler()
.setSelectedCols(new String[]{"sepal_length", "sepal_width", "petal_length", "petal_width"})
.setOutputCol("features");
KMeans kMeans = new KMeans().setVectorCol("features").setK(3)
.setPredictionCol("prediction_result")
.setPredictionDetailCol("prediction_detail")
.setReservedCols("category")
.setMaxIter(100);
Pipeline pipeline = new Pipeline().add(va).add(kMeans);
pipeline.fit(data).transform(data).print();
}
}然后,选择运行 KMeansExample.main(),可看到正常的输出结果如下(显示篇幅关系,只保留了头两条和末尾2条数据):
category|prediction_result|prediction_detail --------|-----------------|----------------- Iris-setosa|0|0.49148233882941467 0.3017994492572307 0.2067182119133547 Iris-versicolor|1|0.3249474882831926 0.396327539544579 0.2787249721722284 ...... Iris-virginica|2|0.13906038938197507 0.38042216584746935 0.4805174447705556 Iris-virginica|1|0.18304443868954268 0.43146730855314785 0.38548825275730947