- Alink权威指南:机器学习实例入门(Java版)
- Alink教程(Java版)目录
- Alink教程(Java版)代码的运行攻略
- 下载部分示例数据的Java代码
- Alink教程(Java版)的数据和资料链接
- 第1章 Alink快速上手
- 第1.1节 Alink是什么
- 第1.2节 免费下载、安装
- 第1.2.1节 使用 Maven 快速构建 Alink Java 项目
- 第1.2.2节 在集群上运行 Alink Java 任务
- 第1.3节 Alink的功能
- 第1.4节 关于数据和代码
- 第2章 系统概况与核心概念
- 第2.1节 基本概念
- 第2.2节 批式任务与流式任务
- 第2.3节 Alink=A+link
- 第2.4节 Pipeline与PipelineModel
- 第2.5节 触发Alink任务的执行
- 第2.5.1节 批式任务打印输出中间结果
- 第2.6节 模型信息显示
- 第2.7节 文件系统与数据库
- 第2.8节 Schema String
- 第3章 文件系统与数据文件
- 第3.2.4节 读取Parquet文件格式数据
- 第3.2.5节 定时输出流式数据
- 第3.2.6节 读取分区格式数据
- 第4章 数据库与数据表
- 第4.5节 Alink连接Kafka数据源
- 第5章 支持Flink SQL
- 第5.3.4节 Flink与Alink的数据转换
- 第6章 用户定义函数(UDF/UDTF)
- 第7章 基本数据处理
- 第7.6节 数据列的选择
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第10章 特征的转化
- 第11章 构造新特征
- 第12章 从二分类到多分类
- 第13章 常用多分类算法
- 第14章 在线学习
- 第15章 回归的由来
- 第16章 常用回归算法
- 第17章 常用聚类算法
- 第18章 批式与流式聚类
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第22章 单词向量化
- 第23章 情感分析
- 第23.5节 中文情感分析示例
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 第25.1节 深度学习组件简介
- 第25.1.1节 深度学习功能概览
- 第25.1.2节 KerasSequential组件
- 第25.1.3节 深度学习相关插件的下载
- 第25.2节 手写识别MNIST
- 第25.3节 深度回归算法
- 第25.4节 运行TensorFlow模型
- 第25.5节 运行PyTorch模型
- 第25.6节 使用自定义 TensorFlow 脚本
- 第25.7节 运行ONNX模型
- 第26章 图像识别
- 第26.1节 数据准备
- 第26.2节 构造二分类模型
- 第26.3节 使用TF Hub模型
- 第27章 语音识别
- 第27.1节 数据准备
- 第27.2节 提取MFCC特征
- 第27.3节 情绪识别
- 第27.4节 录音人识别
- 第28章 深度文本分析
- 第28.1节 中文情感分析
- 第28.2节 BERT文本向量化
- 第28.3节 BERT文本分类器
- 第29章 模型流
- 第29.1节 “看到”模型流
- 第29.2节 批式训练与模型流
- 第29.3节 流式预测与LocalPredictor
- 第29.4节 PipelineModel构成的模型流
- 第29.5节 线性模型的增量训练
- 第29.6节 模型流的过滤
- 第30章 多并行与多线程
- 第30.1节 并行度(Parallelism)
- 第30.2节 多线程(Multi-threads)
- 第30.3节 LocalPredictor使用线程池
- 第31章 图嵌入表示GraphEmbedding
- 第31.1节 算法简介
- 第31.2节 示例数据
- 第31.3节 计算Embedding
- 第31.4节 查看Embedding
- 第31.5节 分类示例
- 第31.6节 改变训练参数
- 第1章 Alink快速上手
- 在Flink集群部署Alink
- 在易用性方面的小技巧
- 流式组件输出数据的显示(基于Jupyter环境)
- Alink插件下载器
- 第2章 系统概况与核心概念
- Failed to load BLAS警告——Mac OS上解决方法
- 在Linux,Mac下定时执行Alink任务
- Failed to load BLAS警告——Linux上解决方法
- 第3章 文件系统与数据文件
- 第4章 数据库与数据表
- Catalog中设置数据库分区【Alink使用技巧】
- 在MacOS上搭建Kafka
- 在Windows上搭建Kafka
- 第5章 支持Flink SQL
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第11章 构造新特征
- GBDT+LR 一体化模型训练与预测
- GBDT+FM 一体化模型训练及预测
- 第13章 常用的多分类算法
- 第14章 在线学习 Ftrl Demo
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 基于图算法实现金融风控
- 如何使用Alink时间序列算法?
- 如何使用Alink窗口特征生成?
第30.2节 多线程(Multi-threads)
还是以OneHot+GBDT+FM 这个线上推理服务为例,这个服务是有三个推理组件构成,其中OneHot最轻,GBDT次之,FM最重,如果按照之前的并行模型必然导致资源分配不均衡,OneHot分配资源太多,FM分的太少。
加入多线程后我们可以为每一个推理子组件设置并行线程数,我们可以为计算负载较轻的 OneHot 设置2个线程,GBDT次之,设置3个线程,FM最重,设置4个线程,从而让资源分配更加合理,提升推理效率。
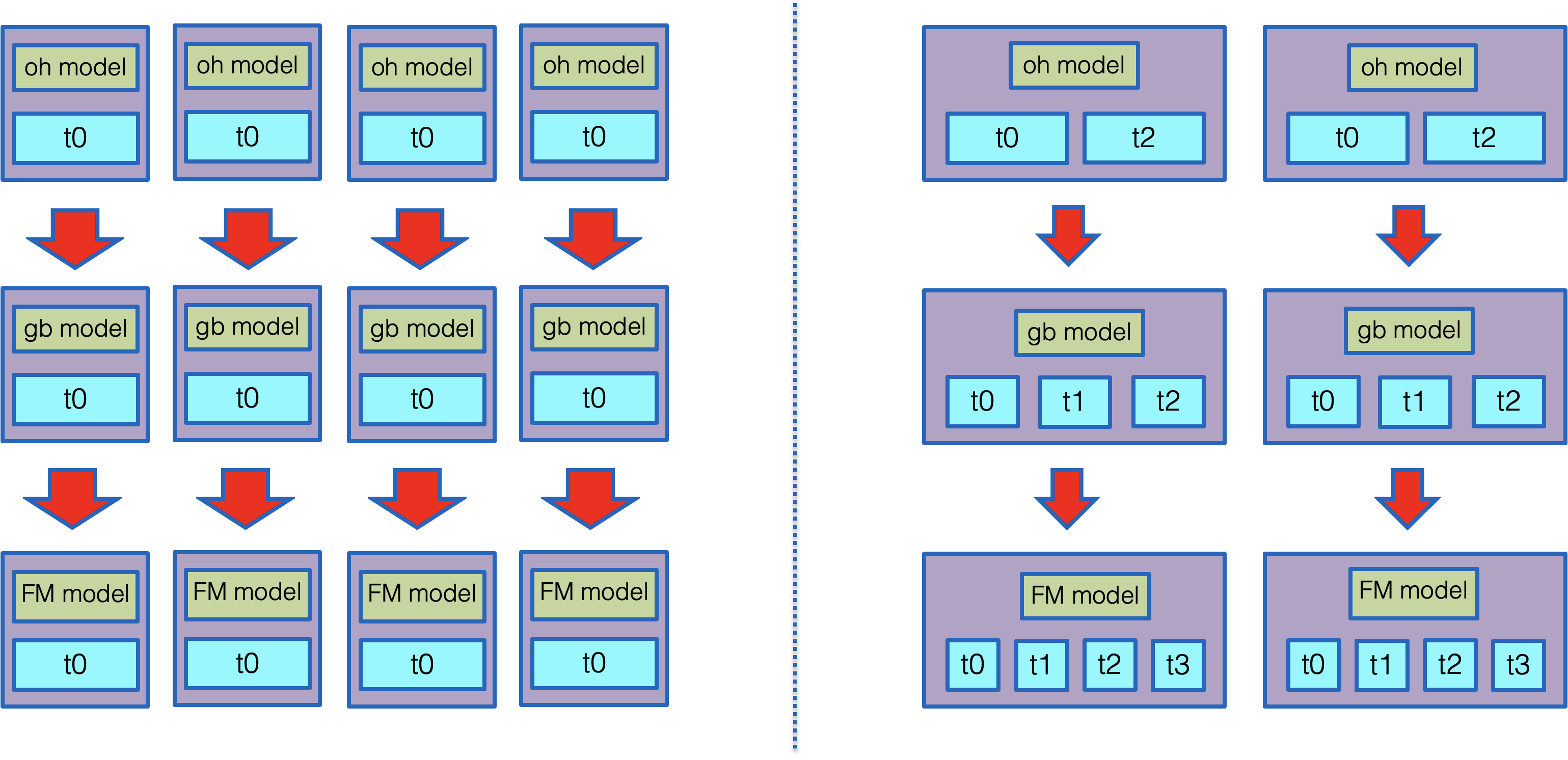
30.2.1 批式组件使用多线程
与第30.1.1节中实验相同,批式任务还是使用4个并行,代码如下:
BatchOperator.setParallelism(4);
KNN批式预测组件KnnPredictBatchOp,使用setNumThreads方法,设置多线程数为2,具体代码如下:
new KnnPredictBatchOp() .setK(3) .setVectorCol(VECTOR_COL_NAME) .setPredictionCol(PREDICTION_COL_NAME) .setNumThreads(2) .linkFrom(getKnnModel(), getTestSet()) .link( new EvalMultiClassBatchOp() .setLabelCol(LABEL_COL_NAME) .setPredictionCol(PREDICTION_COL_NAME) .lazyPrintMetrics() ); BatchOperator.execute();
运行结果如下,当前方式(4个并行,2线程)用时47.884秒,对比第30.1.1节中,批式推理(4个并行,使用默认单线程)用时58.368秒,时间上有显著减少。
Batch mode with Parallelism=4 and NumThreads=2 -------------------------------- Metrics: -------------------------------- Accuracy:0.9719 Macro F1:0.9718 Micro F1:0.9719 Kappa:0.9688 |Pred\Real| 9| 8| 7|...| 2| 1| 0| |---------|---|---|---|---|---|----|---| | 9|971| 4| 12|...| 1| 0| 0| | 8| 4|924| 0|...| 2| 0| 0| | 7| 8| 4|991|...| 13| 0| 1| | ...|...|...|...|...|...| ...|...| | 2| 1| 3| 4|...|994| 2| 1| | 1| 4| 0| 19|...| 9|1133| 1| | 0| 4| 7| 0|...| 10| 0|974| 47 seconds 884.0 milliseconds.
有的读者会问:“为什么时间没有变为1/2呢?”,因为多线程只是缩短了由模型进行推理的时间,但整个流程中,模型加载、读取数据、评估等阶段并没有变化。
30.2.2 流式组件使用多线程
与第30.1.2节中实验相同,流式任务还是使用4个并行,代码如下:
StreamOperator.setParallelism(4);
KNN流式预测组件KnnPredictStreamOp,使用setNumThreads方法,设置多线程数为2,具体代码如下:
getTestStream()
.link(
new KnnPredictStreamOp(getKnnModel())
.setK(3)
.setVectorCol(VECTOR_COL_NAME)
.setPredictionCol(PREDICTION_COL_NAME)
.setNumThreads(2)
)
.link(
new EvalMultiClassStreamOp()
.setLabelCol(LABEL_COL_NAME)
.setPredictionCol(PREDICTION_COL_NAME)
)
.link(
new JsonValueStreamOp()
.setSelectedCol("Data")
.setReservedCols(new String[] {"Statistics"})
.setOutputCols(new String[] {"Accuracy", "Kappa"})
.setJsonPath(new String[] {"$.Accuracy", "$.Kappa"})
)
.print();
StreamOperator.execute();运行结果如下,【此处需要重新运行】。
Statistics|Accuracy|Kappa ----------|--------|----- all|0.9618441971383148|0.9575622468170278 window|0.9618441971383148|0.9575622468170278 window|0.9551020408163265|0.9499737029359898 all|0.9582111436950147|0.9534851720075838 window|0.9582278481012658|0.9535783985526859 all|0.958217270194986|0.9535357505800242 window|0.9533169533169533|0.9481023255970027 all|0.9568733153638814|0.9520503164721521 window|0.968789013732834|0.9652701901164424 all|0.9594056778986468|0.9548648580320753 all|0.958916083916084|0.9543275914197533 window|0.9566294919454771|0.9516305529820548 window|0.9706666666666667|0.9673687978467362 all|0.96057078482914|0.9561659421998374 all|0.9627487667970743|0.9585870444485952 ......
30.2.3 PipelineModel使用多线程
PipelineModel使用多线程,也是使用setNumThreads方法,设置多线程数。PipelineModel的transform方法,可以处理批式数据,也可以处理流式数据,
在批式场景中,PipelineModel使用4并行,2线程的方式预测批式数据的主要代码如下:
BatchOperator.setParallelism(4);
......
getPipelineModel()
.setNumThreads(2)
.transform(getTestSet())
......
BatchOperator.execute();在流式场景中,PipelineModel使用4并行,2线程的方式预测流式数据的主要代码如下:
StreamOperator.setParallelism(4);
......
getPipelineModel()
.setNumThreads(2)
.transform(getTestStream())
......
StreamOperator.execute();