- Alink权威指南:机器学习实例入门(Java版)
- Alink教程(Java版)目录
- Alink教程(Java版)代码的运行攻略
- 下载部分示例数据的Java代码
- Alink教程(Java版)的数据和资料链接
- 第1章 Alink快速上手
- 第1.1节 Alink是什么
- 第1.2节 免费下载、安装
- 第1.2.1节 使用 Maven 快速构建 Alink Java 项目
- 第1.2.2节 在集群上运行 Alink Java 任务
- 第1.3节 Alink的功能
- 第1.4节 关于数据和代码
- 第2章 系统概况与核心概念
- 第2.1节 基本概念
- 第2.2节 批式任务与流式任务
- 第2.3节 Alink=A+link
- 第2.4节 Pipeline与PipelineModel
- 第2.5节 触发Alink任务的执行
- 第2.5.1节 批式任务打印输出中间结果
- 第2.6节 模型信息显示
- 第2.7节 文件系统与数据库
- 第2.8节 Schema String
- 第3章 文件系统与数据文件
- 第3.2.4节 读取Parquet文件格式数据
- 第3.2.5节 定时输出流式数据
- 第3.2.6节 读取分区格式数据
- 第4章 数据库与数据表
- 第4.5节 Alink连接Kafka数据源
- 第5章 支持Flink SQL
- 第5.3.4节 Flink与Alink的数据转换
- 第6章 用户定义函数(UDF/UDTF)
- 第7章 基本数据处理
- 第7.6节 数据列的选择
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第10章 特征的转化
- 第11章 构造新特征
- 第12章 从二分类到多分类
- 第13章 常用多分类算法
- 第14章 在线学习
- 第15章 回归的由来
- 第16章 常用回归算法
- 第17章 常用聚类算法
- 第18章 批式与流式聚类
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第22章 单词向量化
- 第23章 情感分析
- 第23.5节 中文情感分析示例
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 第25.1节 深度学习组件简介
- 第25.1.1节 深度学习功能概览
- 第25.1.2节 KerasSequential组件
- 第25.1.3节 深度学习相关插件的下载
- 第25.2节 手写识别MNIST
- 第25.3节 深度回归算法
- 第25.4节 运行TensorFlow模型
- 第25.5节 运行PyTorch模型
- 第25.6节 使用自定义 TensorFlow 脚本
- 第25.7节 运行ONNX模型
- 第26章 图像识别
- 第26.1节 数据准备
- 第26.2节 构造二分类模型
- 第26.3节 使用TF Hub模型
- 第27章 语音识别
- 第27.1节 数据准备
- 第27.2节 提取MFCC特征
- 第27.3节 情绪识别
- 第27.4节 录音人识别
- 第28章 深度文本分析
- 第28.1节 中文情感分析
- 第28.2节 BERT文本向量化
- 第28.3节 BERT文本分类器
- 第29章 模型流
- 第29.1节 “看到”模型流
- 第29.2节 批式训练与模型流
- 第29.3节 流式预测与LocalPredictor
- 第29.4节 PipelineModel构成的模型流
- 第29.5节 线性模型的增量训练
- 第29.6节 模型流的过滤
- 第30章 多并行与多线程
- 第30.1节 并行度(Parallelism)
- 第30.2节 多线程(Multi-threads)
- 第30.3节 LocalPredictor使用线程池
- 第31章 图嵌入表示GraphEmbedding
- 第31.1节 算法简介
- 第31.2节 示例数据
- 第31.3节 计算Embedding
- 第31.4节 查看Embedding
- 第31.5节 分类示例
- 第31.6节 改变训练参数
- 第1章 Alink快速上手
- 在Flink集群部署Alink
- 在易用性方面的小技巧
- 流式组件输出数据的显示(基于Jupyter环境)
- Alink插件下载器
- 第2章 系统概况与核心概念
- Failed to load BLAS警告——Mac OS上解决方法
- 在Linux,Mac下定时执行Alink任务
- Failed to load BLAS警告——Linux上解决方法
- 第3章 文件系统与数据文件
- 第4章 数据库与数据表
- Catalog中设置数据库分区【Alink使用技巧】
- 在MacOS上搭建Kafka
- 在Windows上搭建Kafka
- 第5章 支持Flink SQL
- 第7章 基本数据处理
- 第8章 线性二分类模型
- 第9章 朴素贝叶斯模型与决策树模型
- 第11章 构造新特征
- GBDT+LR 一体化模型训练与预测
- GBDT+FM 一体化模型训练及预测
- 第13章 常用的多分类算法
- 第14章 在线学习 Ftrl Demo
- 第19章 主成分分析
- 第20章 超参数搜索
- 第21章 文本分析
- 第24章 构建推荐系统
- 第25章 深度学习入门
- 基于图算法实现金融风控
- 如何使用Alink时间序列算法?
- 如何使用Alink窗口特征生成?
第29.4节 PipelineModel构成的模型流
对于一些复杂的场景,不仅分类/回归模型会不断更新,与之对应的数据处理、特征工程阶段也会产生随数据变化的模型,这就要求多个模型要同时更新。将多个阶段PipelineStage当作一个整体,即PipelineModel,这就解决了同时更新的问题。PipelineModel是个“超级”批式模型,包含了其中多个Stage的最新参数,也可以放入到模型流中。从模型流中得到的最新PipelineModel,可以在流式任务或服务不停的前提下,整体替换旧的PipelineModel
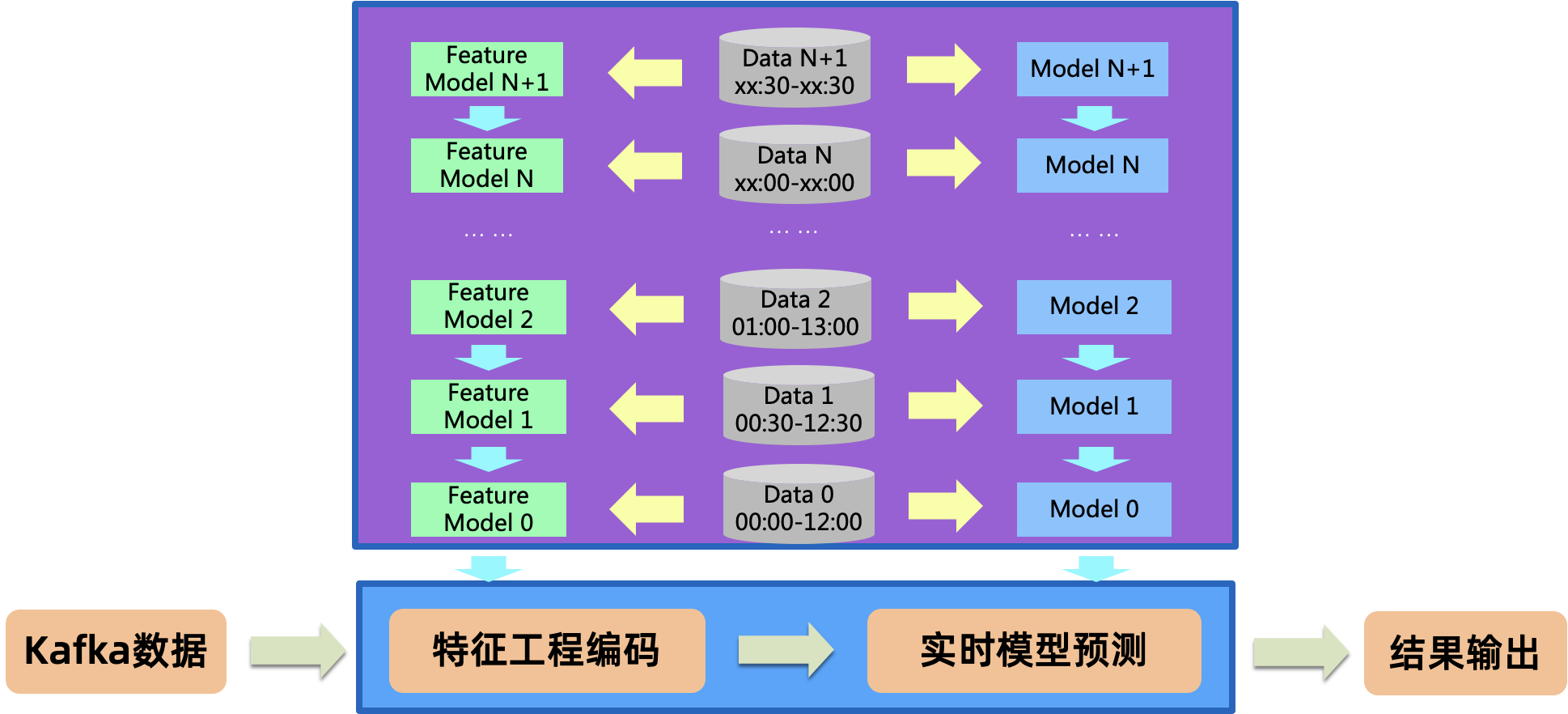
29.4.1 PipelineModel模型流的生成
定义Pipeline包含4个阶段:
- 数值特征进行标准化操作,使用StandardScaler组件
- 离散特征进行One-Hot编码,使用OneHotEncoder组件
- 将各特征列组装为一个特征向量,使用VectorAssembler组件
- LogisticRegression模型
具体代码如下:
Pipeline pipeline = new Pipeline() .add( new StandardScaler() .setSelectedCols(NUMERICAL_COL_NAMES) ) .add( new OneHotEncoder() .setSelectedCols(CATEGORY_COL_NAMES) .setDropLast(false) .setEncode(Encode.ASSEMBLED_VECTOR) .setOutputCols(VEC_COL_NAME) ) .add( new VectorAssembler() .setSelectedCols(ArrayUtils.add(NUMERICAL_COL_NAMES, VEC_COL_NAME)) .setOutputCol(VEC_COL_NAME) ) .add( new LogisticRegression() .setVectorCol(VEC_COL_NAME) .setLabelCol(LABEL_COL_NAME) .setPredictionCol(PREDICTION_COL_NAME) .setReservedCols(LABEL_COL_NAME) .setPredictionDetailCol(PRED_DETAIL_COL_NAME) );
模型训练集来自文件(路径为DATA_DIR + "avazu-small.csv")
CsvSourceBatchOp train_set = new CsvSourceBatchOp() .setFilePath(DATA_DIR + "avazu-small.csv") .setSchemaStr(SCHEMA_STRING);
本节会通过控制训练集的大小,训练出一系列PipelineModel。首先使用5%的训练数据,得到PipelineModel作为后续预测操作的初始模型,保存到文件(路径为DATA_DIR + INIT_PIPELINE_MODEL_FILE),具体代码如下:
pipeline .fit(train_set.sample(0.05)) .save(DATA_DIR + INIT_PIPELINE_MODEL_FILE, true); BatchOperator.execute();
接下来,循环进行PipelineModel的训练。每次train_set的采样率增加5%,形成当前训练集,pipeline训练得到当前的PipelineModel,并通过AppendModelStreamFileSinkBatchOp组件,将其添加到模型流。
for (int i = 2; i <= 20; i++) {
pipeline
.fit(train_set.sample(0.05 * i))
.save()
.link(
new AppendModelStreamFileSinkBatchOp()
.setFilePath(DATA_DIR + PIPELINE_MODEL_STREAM_DIR)
.setNumKeepModel(19)
);
BatchOperator.execute();
System.out.println("\nTrain " + (i - 1) + " PipelineModels.\n");
Thread.sleep(2000);
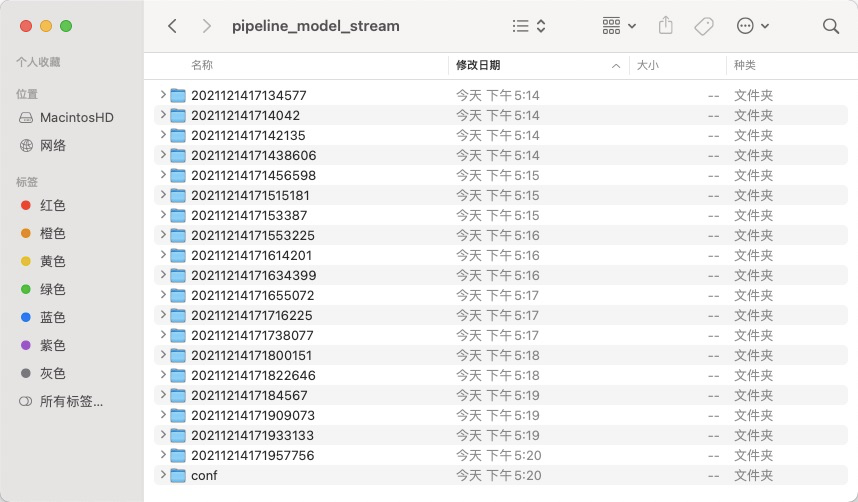
}查看模型流所在文件夹(路径为DATA_DIR + PIPELINE_MODEL_STREAM_DIR),显示如下图。
29.4.2 流式任务中使用PipelineModel模型流
在常规的使用PipelineModel进行流式预测流程的基础上,使用setModelStreamFilePath方法,设置模型流文件夹的路径,就可以通过模型流,更新PipelineModel了。具体代码如下:
StreamOperator <?> predResult = PipelineModel
.load(DATA_DIR + INIT_PIPELINE_MODEL_FILE)
.setModelStreamFilePath(DATA_DIR + PIPELINE_MODEL_STREAM_DIR)
.transform(
new CsvSourceStreamOp()
.setFilePath("http://alink-release.oss-cn-beijing.aliyuncs.com/data-files/avazu-ctr-train-8M.csv")
.setSchemaStr(SCHEMA_STRING)
.setIgnoreFirstLine(true)
);
predResult
.sample(0.0001)
.select("'Pred Sample' AS out_type, *")
.print();
predResult
.link(
new EvalBinaryClassStreamOp()
.setLabelCol(LABEL_COL_NAME)
.setPredictionDetailCol(PRED_DETAIL_COL_NAME)
.setTimeInterval(10)
)
.link(
new JsonValueStreamOp()
.setSelectedCol("Data")
.setReservedCols(new String[] {"Statistics"})
.setOutputCols(new String[] {"Accuracy", "AUC", "ConfusionMatrix"})
.setJsonPath("$.Accuracy", "$.AUC", "$.ConfusionMatrix")
)
.select("'Eval Metric' AS out_type, *")
.print();
StreamOperator.execute();上面的代码为函数Chap29.c_4_2()的内容,同时运行Chap29.c_4_2()和上一节介绍的PipelineModel模型流生成程序Chap29.c_4_1(),即,一边产生新的PipelineModel,一边不断更新预测模型。Chap29.c_4_2()的运行结果如下,其中包含了两种输出,一种是预测结果的采样输出,一种是流式模型评估结果。为了节省篇幅,我们略去大部分预测结果的输出,可以看到流式评估指标有提升。
out_type|click|pred|pred_info
--------|-----|----|---------
out_type|Statistics|Accuracy|AUC|ConfusionMatrix
--------|----------|--------|---|---------------
Pred Sample|0|0|{"0":"0.8824338740627036","1":"0.11756612593729643"}
......
Pred Sample|0|0|{"0":"0.9444219542671783","1":"0.05557804573282166"}
Eval Metric|all|0.8297297852244261|0.6668952993333711|[[3435,5052],[28118,158203]]
Eval Metric|window|0.8297297852244261|0.6668952993333711|[[3435,5052],[28118,158203]]
Pred Sample|0|0|{"0":"0.9398133307532698","1":"0.06018666924673022"}
......
Pred Sample|0|0|{"0":"0.8557456903577869","1":"0.14425430964221309"}
Eval Metric|window|0.8295145505896383|0.6684136785227608|[[3868,5052],[37263,202020]]
Eval Metric|all|0.8296091970628269|0.6676815710617451|[[7303,10104],[65381,360223]]
Pred Sample|0|0|{"0":"0.9778352680682564","1":"0.02216473193174362"}
......
Pred Sample|0|0|{"0":"0.7777008376593497","1":"0.22229916234065028"}
Eval Metric|window|0.8339849908557735|0.6724791468610775|[[3245,3411],[38709,208347]]
Eval Metric|all|0.8312026443794737|0.6690371151657384|[[10548,13515],[104090,568570]]
Pred Sample|0|0|{"0":"0.878261454337365","1":"0.12173854566263498"}
......
Pred Sample|0|0|{"0":"0.9112290282109129","1":"0.0887709717890871"}
Eval Metric|all|0.8322811498899614|0.6725518118953981|[[14109,17319],[141577,774390]]
Eval Metric|window|0.835278770664454|0.6831684163174138|[[3561,3804],[37487,205820]]
Pred Sample|0|0|{"0":"0.7908054547875323","1":"0.20919454521246772"}
......
Pred Sample|0|0|{"0":"0.9038244759100549","1":"0.09617552408994512"}
Eval Metric|window|0.8333604847521605|0.6792313027625998|[[3957,4390],[37549,205779]]
Eval Metric|all|0.8325076934624334|0.6738985382938575|[[18066,21709],[179126,980169]]
Pred Sample|1|0|{"0":"0.9126242140286693","1":"0.08737578597133067"}
Pred Sample|0|0|{"0":"0.8954749661946126","1":"0.10452503380538736"}29.4.3 LocalPredictor使用PipelineModel模型流
LocalPredictor本身没有提供接入模型流的方法,需要在其导入的PipelineModel中进行设置。如下面代码所示,导入初始模型(模型文件路径:DATA_DIR + INIT_PIPELINE_MODEL_FILE),得到PipelineModel,然后使用setModelStreamFilePath方法,设置模型流所在的文件夹路径。再将包含模型流设置的PipelineModel保存为模型文件(路径为DATA_DIR + PIPELINEMODEL_WITH_MODELSTREAM_FILE)。
PipelineModel .load(DATA_DIR + INIT_PIPELINE_MODEL_FILE) .setModelStreamFilePath(DATA_DIR + PIPELINE_MODEL_STREAM_DIR) .save(DATA_DIR + PIPELINEMODEL_WITH_MODELSTREAM_FILE, true); BatchOperator.execute();
LocalPredictor构造函数中输入包含模型流设置的PipelineModel模型文件路径(DATA_DIR + PIPELINEMODEL_WITH_MODELSTREAM_FILE),这样就得到了接入PipelineModel模型流的LocalPredictor,具体代码如下:
LocalPredictor localPredictor = new LocalPredictor(DATA_DIR + PIPELINEMODEL_WITH_MODELSTREAM_FILE, SCHEMA_STRING);
我们输入一条数据,接下来,对该数据循环进行预测,预测间隔2秒,预测结束后,调用localPredictor的close方法,释放资源,结束对模型流文件夹的监控。
Object[] input = new Object[] {
"10000949271186029916", "1", "14102100", "1005", 0, "1fbe01fe", "f3845767", "28905ebd",
"ecad2386", "7801e8d9", "07d7df22", "a99f214a", "37e8da74", "5db079b5", "1", "2",
15707, 320, 50, 1722, 0, 35, -1, 79};
for (int i = 1; i <= 100; i++) {
System.out.print(i + "\t");
System.out.println(ArrayUtils.toString(localPredictor.predict(input)));
Thread.sleep(2000);
}
localPredictor.close();上面的代码为函数Chap29.c_4_3()的内容,同时运行Chap29.c_4_3()和第29.4.1节介绍的PipelineModel模型流生成程序Chap29.c_4_1(),即,一边产生新的PipelineModel,一边不断更新localPredictor的预测模型。Chap29.c_4_3()的运行的部分结果如下所示,因为每次预测的都是同一个数据,如果模型没有变化,结果也是相同的,我们从运行结果上,可以看出预测结果在发生变化,说明了localPredictor在根据PipelineModel模型流更新预测模型。
18 1,0,{"0":"0.7017719823271469","1":"0.2982280176728531"}
19 1,0,{"0":"0.7017719823271469","1":"0.2982280176728531"}
20 1,0,{"0":"0.7017719823271469","1":"0.2982280176728531"}
21 1,0,{"0":"0.7017719823271469","1":"0.2982280176728531"}
22 1,0,{"0":"0.7775813140410618","1":"0.2224186859589382"}
23 1,0,{"0":"0.7775813140410618","1":"0.2224186859589382"}
24 1,0,{"0":"0.7775813140410618","1":"0.2224186859589382"}
25 1,0,{"0":"0.7775813140410618","1":"0.2224186859589382"}
26 1,0,{"0":"0.7775813140410618","1":"0.2224186859589382"}
27 1,0,{"0":"0.7438455030430449","1":"0.25615449695695514"}
28 1,0,{"0":"0.7438455030430449","1":"0.25615449695695514"}
29 1,0,{"0":"0.7438455030430449","1":"0.25615449695695514"}
30 1,0,{"0":"0.7438455030430449","1":"0.25615449695695514"}
31 1,0,{"0":"0.7438455030430449","1":"0.25615449695695514"}
32 1,0,{"0":"0.7438455030430449","1":"0.25615449695695514"}
33 1,0,{"0":"0.7438455030430449","1":"0.25615449695695514"}
34 1,0,{"0":"0.7438455030430449","1":"0.25615449695695514"}
35 1,0,{"0":"0.7438455030430449","1":"0.25615449695695514"}
36 1,0,{"0":"0.7503320064425485","1":"0.2496679935574515"}
37 1,0,{"0":"0.7503320064425485","1":"0.2496679935574515"}
38 1,0,{"0":"0.7503320064425485","1":"0.2496679935574515"}